Implementing an arXiv MCP Server with Quarkus in Java
For my recent presentation at SnowCamp on AI Standards & Protocols for AI Agents, I decided to build an MCP server to access the arXiv research paper website where pre-print versions are published and shared with the community.
My goal was to shed light on some lesser-known aspects of the Model Context Protocol:
- 🛠️ While the majority of MCP servers use the tools feature to expose actions that LLMs can request to call,
- 📄 An MCP server can also share resources (and resource templates), exposing various static assets the AI app might be interested in,
- ✏️ And prompts (and prompt templates) that users can access and reuse to utilize the MCP server effectively.
For the impatient, feel free to go straight to the GitHub repository for the full source code. The README.md file gives instructions on how to build, run, configure, and use the server.
Read more...Building a Research Assistant with the Interactions API in Java
First of all, dear readers, let me wish you a happy new year! This is my first post on this blog for 2026. I’m looking forward to continuing sharing interesting content with you.
During my holiday break, I wanted to put my recent Java implementation of the Gemini Interactions API to the test. I implemented and released it with the help of Antigravity. My colleague Shubham Saboo and Gargi Gupta wrote a tutorial on how to build an AI research agent with Google Interactions API & Gemini 3. I thought this was a great opportunity to replicate this example in Java using my Interactions API Java SDK.
Read more...Implementing the Interactions API with Antigravity
Google and DeepMind have announced the Interactions API, a new way to interact with Gemini models and agents.
Here are some useful links to learn more about this new API:
- An announcement is available on Google’s Keywords blog:
Interactions API: A unified foundation for models and agents - A more detailed article is available on Google’s developers blog:
Building agents with the ADK and the new Interactions API - The newly released Gemini Deep Research agent is now available via the Interactions API as well:
Build with Gemini Deep Research - The official documentation of the Interactions API.
About the Interactions API
The Rationale and Motivation
The Interactions API was introduced to address a shift in AI development, moving from simple, stateless text generation to more complex, multi-turn agentic workflows. It serves as a dedicated interface for systems that require memory, reasoning, and tool use. It provides a unified interface for both simple LLM calls and more complex agent calls.
Read more...Gemini Is Cooking Bananas Under Antigravity
What a wild title, isn’t it? It’s a catchy one, not generated by AI, to illustrate this crazy week of announcements by Google. Of course, there are big highlights like Gemini 3 Pro, Antigravity, or Nano Banana Pro, but not only, and this is the purpose of the article to share with you everything, including links to all the interesting materials about those news.
Gemini 3 Pro
The community was eagerly anticipating the release of Gemini 3. Gemini 3 Pro is a state-of-the-art model, with excellent multimodal capabilities, advanced reasoning, excellent at coding, and other agentic activities.
Read more...Semantic Document Similarity: Finding related articles with vector embedding models
When you enjoyed reading an article on a blog, you might be interested in other, similar articles. As a blog author, you want to surface that relevant content to your readers to keep them engaged. For a long time, I’ve wanted to add a “Similar articles” section to my posts, but I never quite found a simple and effective way to do it. Hugo (the static stite generator I’m using) has a related content concept, but it wasn’t really what I was after.
Read more...Driving a web browser with Gemini's Computer Use model in Java
In this article, I’ll guide you through the process of programmatically interacting with a web browser using the new Computer Use model in Gemini 2.5 Pro. We’ll accomplish this in Java ☕ leveraging Microsoft’s powerful Playwright Java SDK to handle the browser automation.
The New Computer Use Model
Unveiled in this announcement article and made available in public preview last month, via the Gemini API on Google AI Studio and Vertex AI, Gemini 2.5 Pro introduces a pretty powerful “Computer Use” feature.
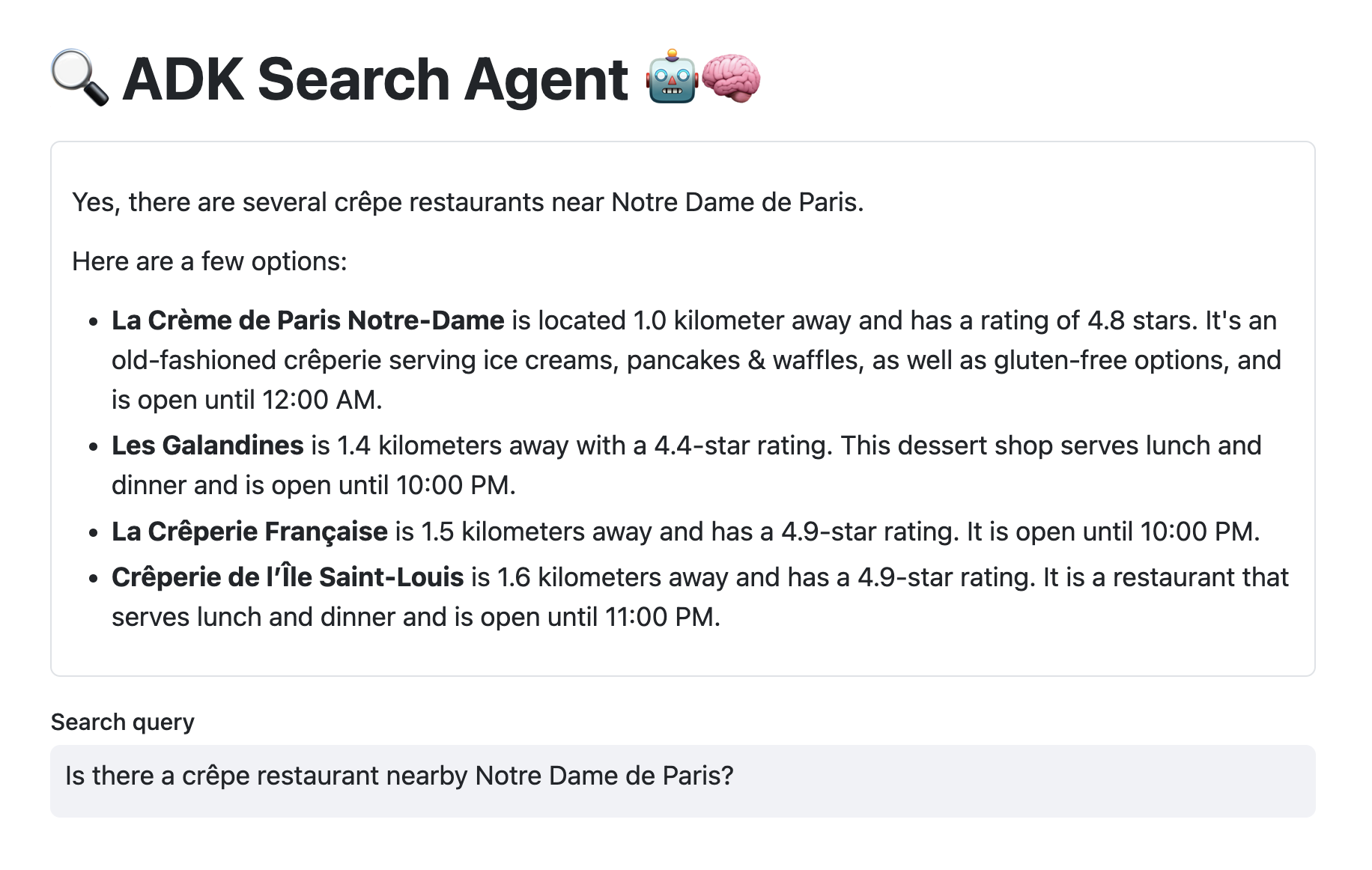
Read more...A Javelit frontend for an ADK agent
Continuing my journey with Javelit, after creating a frontend for “Nano Banana” to generate images and a chat interface for a LangChain4j-based Gemini chat model, I decided to see how I could integrate an ADK agent with a Javelit frontend.
The Javelit interface for an ADK search agent
Creating a Javelit chat interface for LangChain4j
Yesterday, I uncovered the Javelit project in this article where I built a small frontend to create and edit images with Google’s Nano Banana image model.
Javelit is an open source project inspired by Streamlit from the Python ecosystem to enable rapid prototyping and deployment of applications in Java.
Read more...Javelit to create quick interactive app frontends in Java
Have you ever heard of Javelit? It’s like Streamlit in the Python ecosystem, but for the Java developer! I was lucky that the project creator reached out and introduced me to this cool little tool!
Javelit is a tool to quickly build interactive app frontends in Java, particularly for data apps, but it’s not limited to them. It helps you quickly develop rapid prototypes, with a live-reload loop, so that you can quickly experiment and update the app instantly.
Read more...Creative Java AI agents with ADK and Nano Banana 🍌
Large Language Models (LLMs) are all becoming “multimodal”. They can process text, but also other “modalities” in input, like pictures, videos, or audio files. But models that output more than just text are less common…
Recently, I wrote about my experiments with Nano Banana 🍌 (in Java), a Gemini chat model flavor that can create and edit images. This is pretty handy in particular for interactive creative tasks, like for example a marketing assistant that would help you design a new product, by describing it, by futher tweaking its look, by exposing it in different settings for marketing ads, etc.
Read more...