Tale of a Groovy Spark in the Cloud
As I recently joined Google’s developer advocacy team for Google Cloud Platform, I thought I could have a little bit of fun with combining my passion for Apache Groovy with some cool cloudy stuff from Google! Incidentally, Paolo Di Tommaso tweeted about his own experiments with using Groovy with Apache Spark, and shared his code on Github:
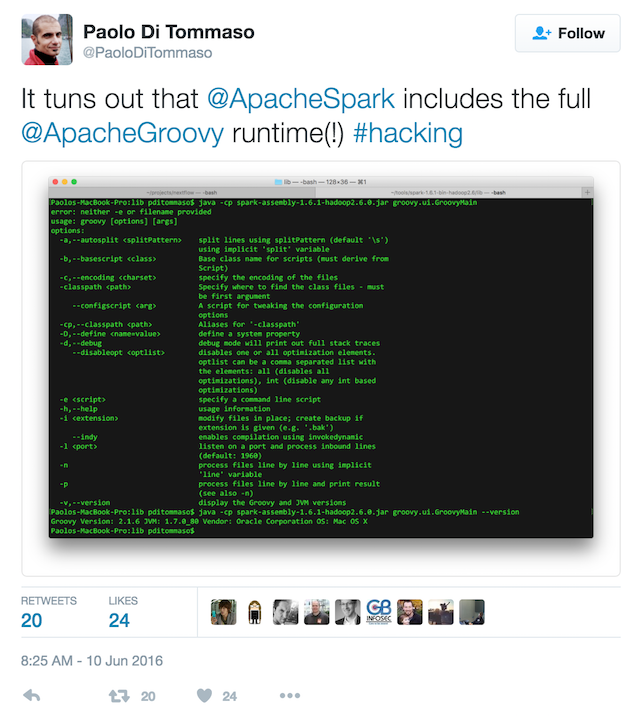
I thought that would be a nice fun first little project to try to use Groovy to run a Spark job on Google Cloud Dataproc! Dataproc manages Hadoop & Spark for you: it’s a service that provides managed Apache Hadoop, Apache Spark, Apache Pig and Apache Hive. You can easily process big datasets at low cost, control those costs by quickly creating managed clusters of any size and turning them off where you’re done. In addition, you can obviously use all the other Google Cloud Platform services and products from Dataproc (ie. store the big datasets in Google Cloud Storage, on HDFS, through BigQuery, etc.)
More concretely,, how do you run a Groovy job in Google Cloud Dataproc’s managed Spark service? Let’s see that in action!
To get started, I checked out Paolo’s samples from Github, and I even groovy-fied the Pi calculation example (based on this approach) to make it a bit more idiomatic:
package org.apache.spark.examples
import groovy.transform.CompileStatic
import org.apache.spark.SparkConf
import org.apache.spark.api.java.JavaSparkContext
import org.apache.spark.api.java.function.Function
import org.apache.spark.api.java.function.Function2
import scala.Function0
@CompileStatic
final class GroovySparkPi {
static void main(String[] args) throws Exception {
def sparkConf = new SparkConf().setAppName("GroovySparkPi")
def jsc = new JavaSparkContext(sparkConf)
int slices = (args.length == 1) ? Integer.parseInt(args[0]) : 2
int n = 100000 * slices
def dataSet = jsc.parallelize(0..
def mapper = {
double x = Math.random() * 2 - 1
double y = Math.random() * 2 - 1
return (x * x + y * y < 1) ? 1 : 0
}
int count = dataSet
.map(mapper as Function)
.reduce({int a, int b -> a + b} as Function2)
println "Pi is roughly ${4.0 * count / n}"
jsc.stop()
}
}
You can also use a Groovy script instead of a full-blown class, but you need to make the script serializable with a little trick, by specifying a custom base script class. You need a custom Serializable Script:
import groovy.transform.BaseScript
@BaseScript SerializableScript baseScript
And in your job script, you should specify this is your base script class with:
abstract class SerializableScript extends Script implements Serializable {}
The project comes with a Gradle build file, so you can compile and build your project with the gradle jar command to quickly create a JAR archive.
Now let’s focus on the Cloud Dataproc part of the story! I basically simply followed the quickstart guide. I used the Console (the UI web interface), but you could as well use the gcloud command-line tool as well. You’ll need an account of course, and enable billing, as running Spark jobs on clusters can be potentially expensive, but don’t fear, there’s a free trial that you can take advantage of! You can also do some quick computation with the calculator to estimate how much a certain workload will cost you. In my case, as a one time off job, this is a sub-dollar bill that I have to pay.
Let’s create a brand new project:
We’re going to create a Spark cluster, but we’ll need to enable the Compute Engine API for this to work, so head over to the hamburger menu, select the API manager item, and enable it:
Select the Dataproc menu from the hamburger, which will allow you to create a brand new Spark cluster:
Create a cluster as follows (the smallest one possible for our demo):
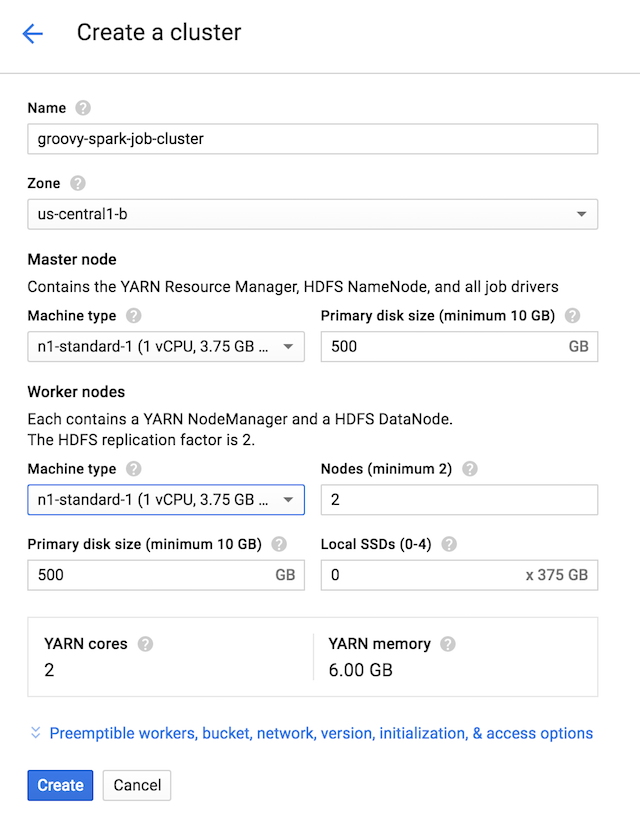
Also, in case you have some heavy & expensive workloads, for which it doesn’t matter much if they can be interrupted or not (and then relaunched later on), you could also use Preemptible VMs to further lower the cost.
We created a JAR archive for our Groovy Spark demo, and for the purpose of this demo, we’ll push the JAR into Google Cloud Storage, to create Spark jobs with this JAR (but there are other ways to push your job’s code automatically as well). From the menu again, go to Cloud Storage, and create a new bucket:
Create a bucket with a name of your choice (we’ll need to remember it when creating the Spark jobs):

Once this bucket is created, click on it, and then click on the “upload files” button, to upload your JAR file:
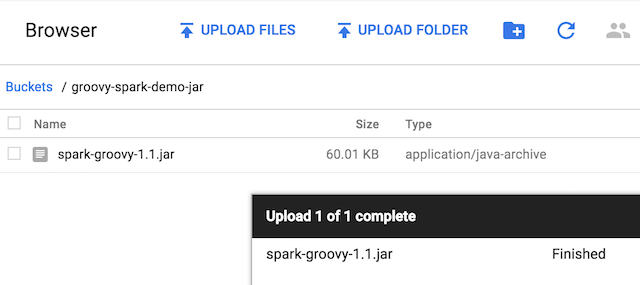
We can come back to the Dataproc section, clicking on the Jobs sub-menu to create a new job:
We’ll create a new job, using our recently created cluster. We’ll need to specify the location of the JAR containing our Spark job: we’ll use the URL gs://groovy-spark-demo-jar/spark-groovy-1.1.jar. The gs:// part corresponds to the Google Cloud Storage protocol, as that’s where we’re hosting our JAR. Then groovy-spark-demo-jar/ corresponds to the name of the bucket we created, and then at the end, the name of the JAR file. We’ll use an argument of 1000 to specify the number of parallel computations of our Pi approximation algorithm we want to run:
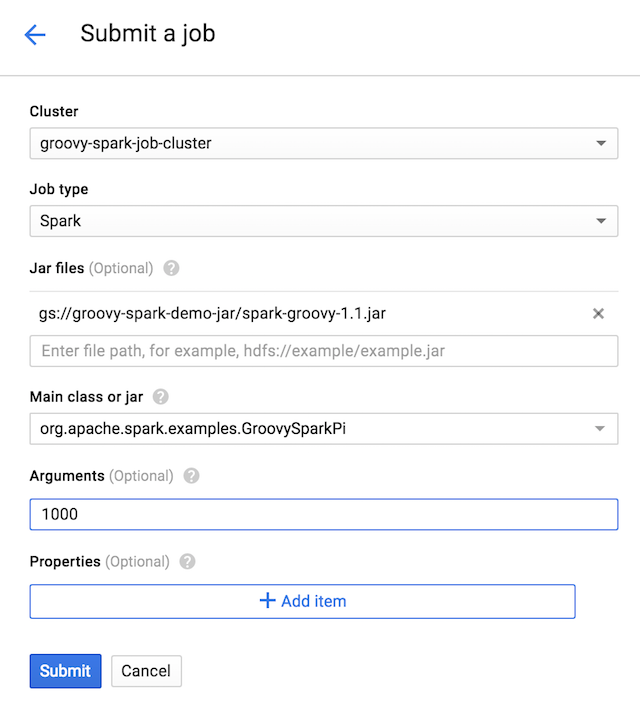
Click Submit, and here we go, our Groovy Spark job is running in the cloud on our 2-node cluster!
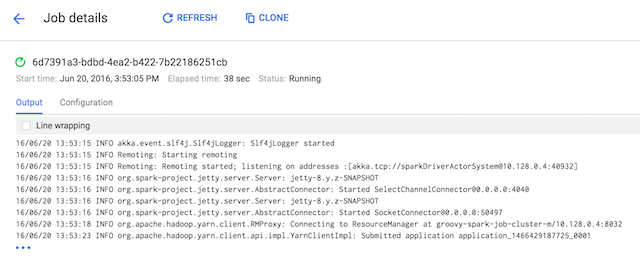
Just a bit of setup through the console, which you can also do from the command-line, and of course a bit of Groovy code to do the computation. Be sure to have a look at the quick start guide, which gives more details than this blog post, and you can look at some other Groovy Spark samples thanks to Paolo on his Github project.