What can we learn from million lines of Groovy code on Github?
Github and Google recently announced and released the Github archive to BigQuery, liberating a huge dataset of source code in multiple programming languages, and making it easier to query it and discover some insights.
Github explained that the dataset comprises over 3 terabytes of data, for 2.8 million repositories, 145 million commits over 2 billion file paths! The Google Cloud Platform blog gave some additional pointers to give hints about what’s possible to do with the querying capabilities of BigQuery. Also, you can have a look at the getting started guide with the steps to follow to have fun yourself with the dataset.
My colleagues Felipe gave some interesting stats about the top programming languages, or licenses, while Francesc did some interesting analysis of Go repositories. So I was curious to investigate myself this dataset to run some queries about the Groovy programming language!
Without further ado, let’s dive in!
If you don’t already have an account of the Google Cloud Platform, you’ll be able to get the free trial, with $300 of credits to discover and have fun with all the products and services of the platform. Then, be sure to have a look at the Github dataset getting started guide I’ve mentioned above which can give you some ideas of things to try out, and the relevant steps to start tinkering with the data.
In the Google Cloud Platform console, I’ve created an empty project (for me, called “github-groovy-files”) that will host my project and the subset of the whole dataset to focus on the Groovy source files only.
Next, we can go to the Github public dataset on BigQuery:
https://bigquery.cloud.google.com/dataset/bigquery-public-data:github_repos
I created a new dataset called “github”, whose location is in the US (the default). Be sure to keep the default location in the US as the Github dataset is in that region already.
I launched the following query to list all the Groovy source files, and save them in a new table called “files” for further querying:
SELECT *
FROM [bigquery-public-data:github_repos.files]
WHERE RIGHT(path, 7) = '.groovy'
Now that I have my own subset of the dataset with only the Groovy files, I ran a count query to know the number of Groovy files available:
SELECT COUNT(*)
FROM [github-groovy-files:github.files]
There are 743 070 of Groovy source files!
I was curious to see if there were some common names of Groovy scripts and classes that would appear more often than others:
SELECT TOP(filename, 24), COUNT(\*) as n
FROM (
SELECT LAST(SPLIT(path, '/')) as filename
FROM [github.files]
)
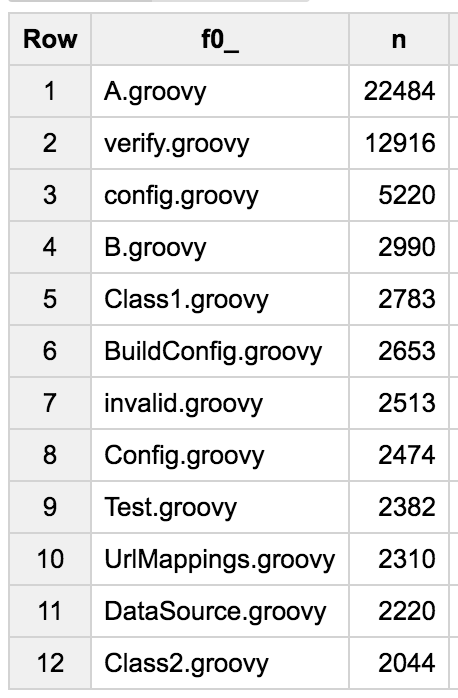
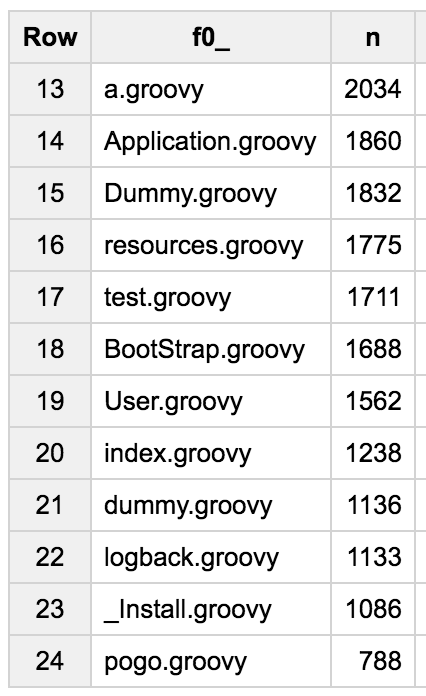
I was surprised to see A.groovy being the most frequent file name! I haven’t dived deeper yet, but I’d be curious to see what’s in those A.groovy files, as well as B.groovy or a.groovy in 4th and 13th positions respectively.
Apache Groovy is often used for various automation tasks, and I’ve found many Maven or Jenkins scripts to check that a certain task or job terminated correctly thanks to scripts called verify.groovy.
Files like BuildConfig.groovy, Config.groovy, UrlMappings.groovy, DataSource.groovy, BootStrap.groovy clearly come from the usual files found in Grails framework web applications.
You can also see configuration files like logback.groovy to configure the Logback logging library.
You don’t see usage of the Gradle build automation tool here, because I only selected files with a .groovy extension, and not files with the .gradle extension. But we’ll come back to Gradle in a moment.
So far, we’ve looked at the file names only, not at their content. That’s where we need another table, coming from the “contents” table of the dataset, that we’ll filter thanks to the file names we’ve saved in our “files” table, thanks to this query:
SELECT *
FROM [bigquery-public-data:github_repos.contents]
WHERE id IN (
SELECT id
FROM [github.files]
)
As this is a lot of content, I had to save the result of the query in a new table called “contents”, and I had to check the box “allow large results” in the options pane that you can open thanks to the “Show options” button below the query editor.
From the 743 070 files, how many lines of Groovy code do you think there are in them? For that purpose, we need to split the raw content of the files per lines, as follows:
SELECT COUNT(line) total_lines
FROM (
SELECT SPLIT(content, '\n') AS line
FROM [github-groovy-files:github.contents]
)
We have 16,464,376 lines of code over the our 743,070 Groovy files. That’s an average of 22 lines per file, which is pretty low! It would be more interesting to draw some histogram to see the distribution of those lines of code. We can use quantiles to have a better idea of the distribution with this query with 10 quantiles:
SELECT QUANTILES(total_lines, 10) AS q
FROM (
SELECT COUNT(line) total_lines
FROM (
SELECT SPLIT(content, '\n') AS line, id
FROM [github-groovy-files:github.contents]
)
GROUP BY id
)
Which gives this resulting table:
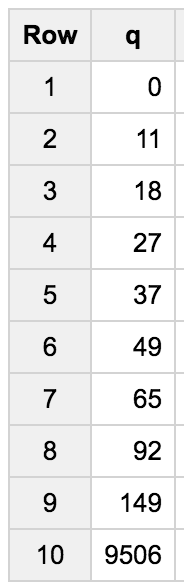
There are files with 0 lines of code! And the biggest one is 9506 lines long! 10% are 11 lines long or less, half are 37 lines or less, etc. And 10% are longer than 149 lines.
Let’s now have a look at packages and imports for a change.
Do you know what are the most frequent packages used?
SELECT package, COUNT(*) count
FROM (
SELECT REGEXP_EXTRACT(line, r' (\[a-z0-9\\.\_\]\*)\\.') package, id
FROM (
SELECT SPLIT(content, '\n') line, id
FROM [github-groovy-files:github.contents]
WHERE content CONTAINS 'import'
HAVING LEFT(line, 6)='import'
)
GROUP BY package, id
)
GROUP BY 1
ORDER BY count DESC
LIMIT 30;
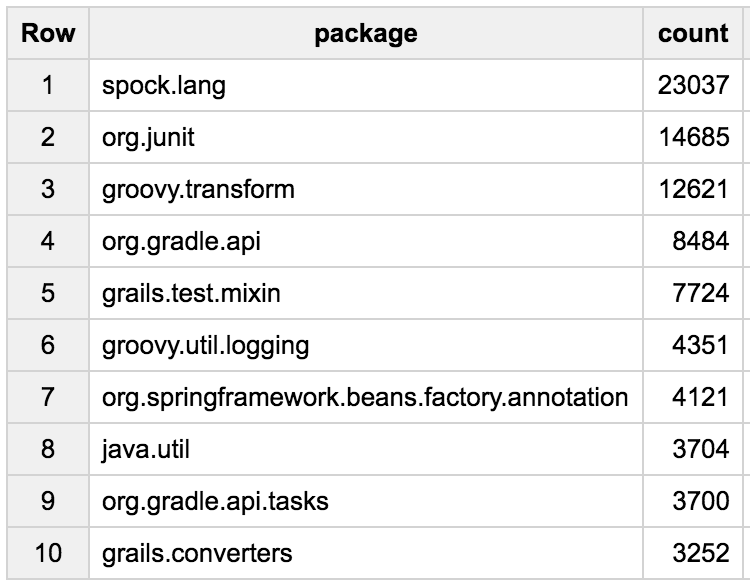
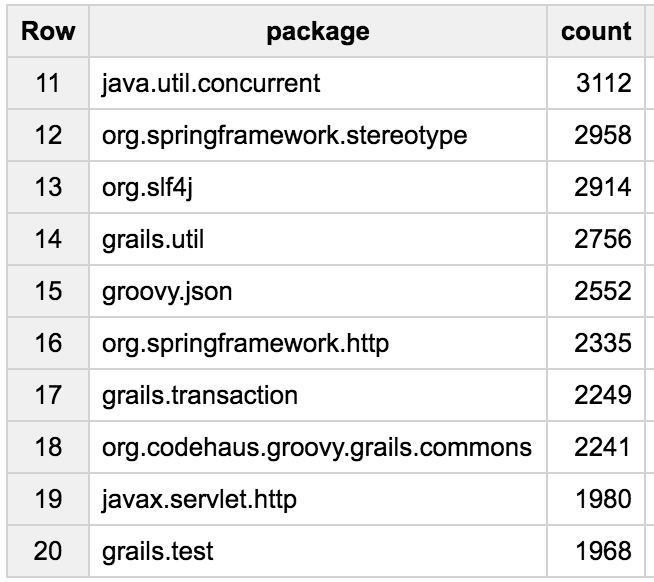
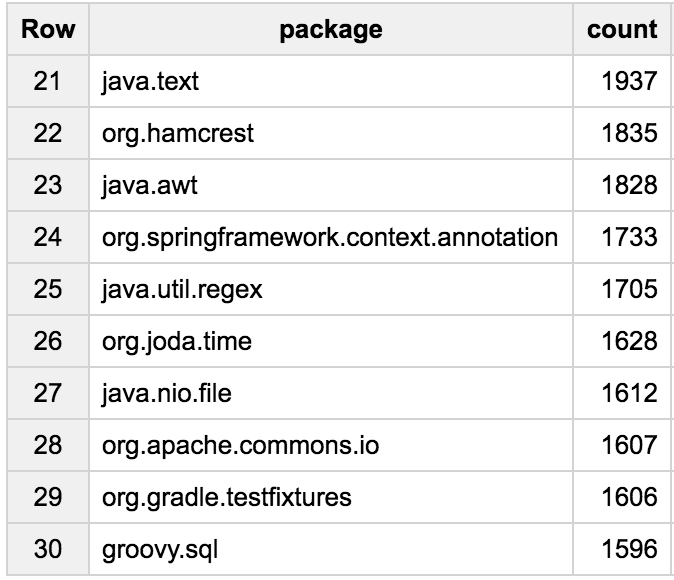
The Spock and JUnit testing frameworks are the most widely used packages, showing that Groovy is used a lot for testing! We also see a lot of Grails and Gradle related packages, and some logging, some Spring, Joda-Time, Java util-concurrent or servlets, etc.
We can zoom in the groovy.* packages with:
SELECT package, COUNT(*) count
FROM (
SELECT REGEXP_EXTRACT(line, r' ([a-z0-9\._]\*)\.') package, id
FROM (
SELECT SPLIT(content, '\n') line, id
FROM [github-groovy-files:github.contents]
WHERE content CONTAINS 'import'
HAVING LEFT(line, 6)='import'
)
GROUP BY package, id
)
WHERE package LIKE 'groovy.%'
GROUP BY 1
ORDER BY count DESC
LIMIT 10;
And groovy.transform is unsurprisingly the winner, as it’s where all Groovy AST transformations reside, providing useful code generation capabilities saving developers from writing tedious repetitive code for common tasks (@Immutable, @Delegate, etc.) After transforms come groovy.util.logging for logging, groovy.json for working with JSON files, groovy.sql for interacting with databases through JDBC, groovy.xml to parse and produce XML payloads, and groovy.text for templating engines:
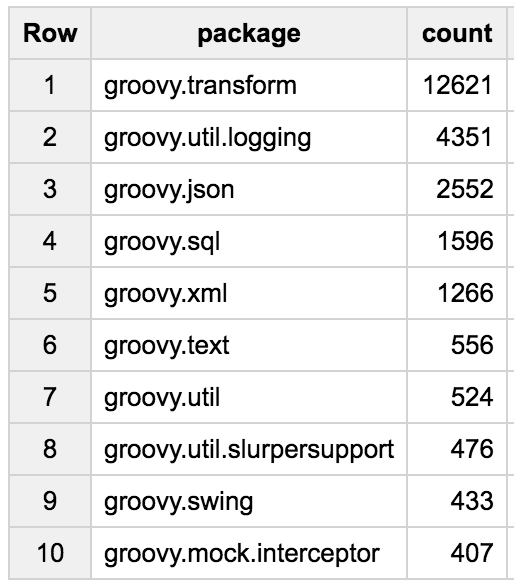
With Groovy AST transformations being so prominent, we can also look at the most frequently used AST transformations with:
SELECT TOP(class_name, 10) class_name, COUNT(*) count
FROM (
SELECT REGEXP_EXTRACT(line, r' [a-z0-9\._]*\.([a-zA-Z0-9_]*)') class_name, id
FROM (
SELECT SPLIT(content, '\n') line, id
FROM [github-groovy-files:github.contents]
WHERE content CONTAINS 'import'
)
WHERE line LIKE '%groovy.transform.%'
GROUP BY class_name, id
)
WHERE class_name != 'null'
And we get:
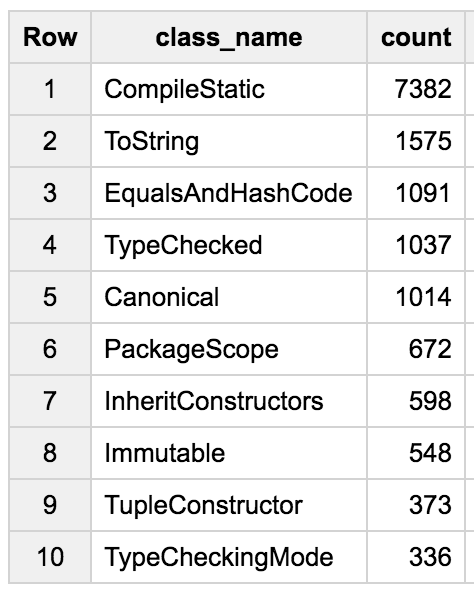
The @CompileStatic transformation is the king! Followed by @ToString and @EqualsAndHashCode. But then @TypeChecked is fourth, showing that the static typing and compilation support of Groovy is really heavily used. Other interesting transforms used follow with @Canonical, @PackageScope, @InheritConstructors, @Immutable or @TupleConstructor.
As I was exploring imports, I also wondered whether aliased imports was often seen or not:
SELECT aliased, count(aliased) total
FROM (
SELECT REGEXP\_MATCH(line, r'.* (as) .*') aliased
FROM (
SELECT SPLIT(content, '\n') AS line
FROM [github-groovy-files:github.contents]
)
WHERE line CONTAINS 'import '
)
GROUP BY aliased
LIMIT 100
Interestingly, there are 2719 aliased imports over 765281 non aliased ones, that’s about 0.36%, so roughly 1 import … as … for 300 normal imports.
And with that, that rounds up my exploration of Groovy source files on Github! It’s your turn to play with the dataset, and see if there are interesting findings to be unveiled! Did you find anything?