A poor-man assistant with speech recognition and natural language processing
All sorts of voice-powered assistants are available today, and chat bots are the new black! In order to illustrate how such tools are made, I decided to create my own little basic conference assistant, using Google’s Cloud Speech API and Cloud Natural Language API. This is a demo I actually created for the Devoxx 2016 keynote, when Stephan Janssen invited me on stage to speak about Machine Learning. And to make this demo more fun, I implemented it with a shell script, some curl calls, plus some other handy command-line tools.
So what is this “conference assistant” all about? Thanks for asking. The idea is to ask questions to this assistant about topics you’d like to see during the conference. For example: “Is there a talk about the Google Cloud Vision API?”. You send that voice request to the Speech API, which gives you back the transcript of the question. You can then use the Natural Language API to process that text to extract the relevant topic in that question. Then you query the conference schedule to see if there’s a talk matching the topic.
Let’s see this demo into action, before diving into the details.
So how did I create this little command-line conference assistant? Let’s start with a quick diagram showing the whole process and its steps:
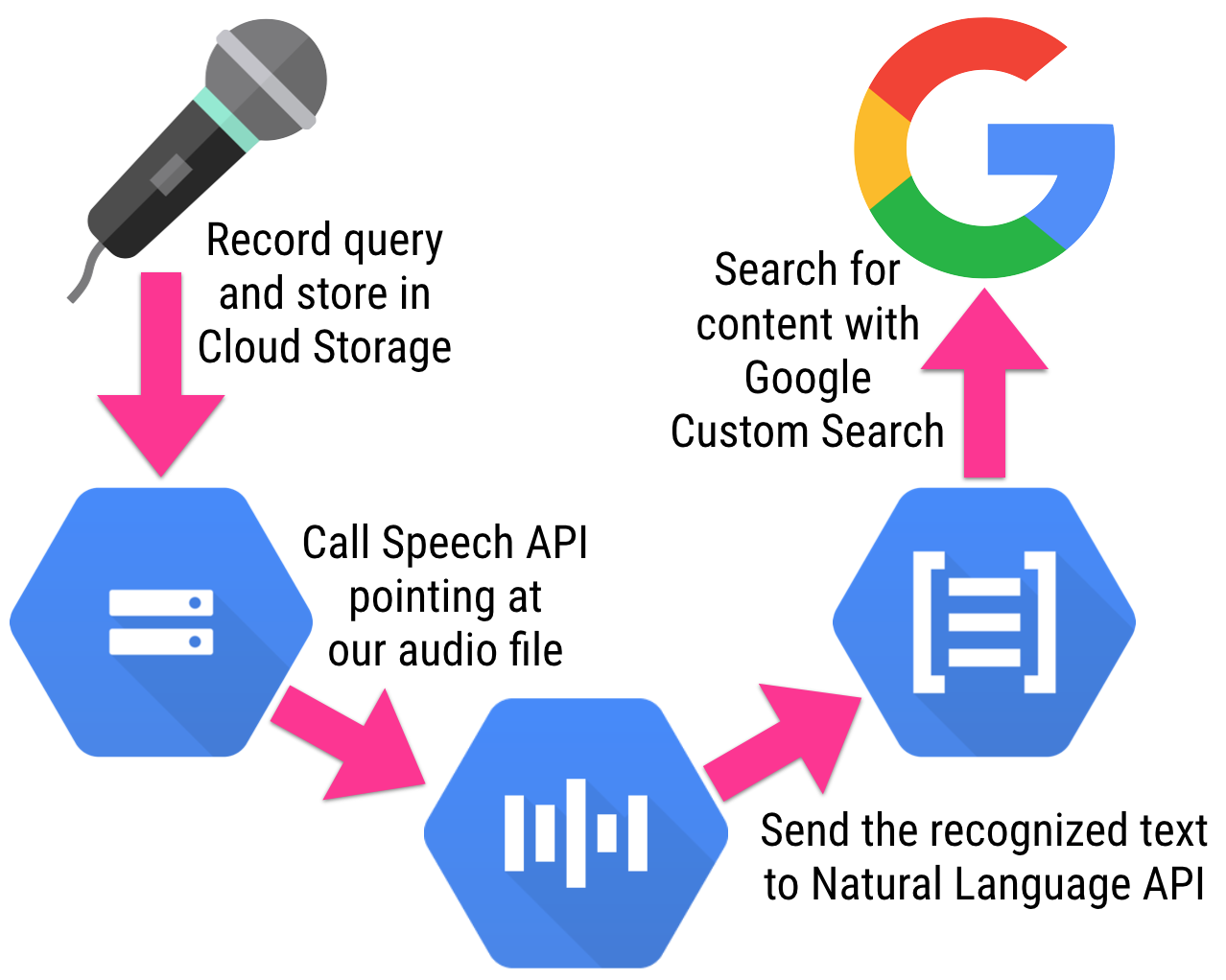
- First, I record the audio using the sox command-line tool.
- The audio file is saved locally, and I upload it to Google Cloud Storage (GCS).
- I then call the Speech API, pointing it at my recorded audio file in GCS, so that it returns the text it recognized from the audio.
- I use the jq command line tool to extract the words from the returned JSON payload, and only the words I’m interested in (basically what appears after the “about” part of my query, ie. “a talk about machine learning”)
- Lastly, I’m calling a custom search engine that points at the conference website schedule, to find the relevant talks that match my search query.
Let’s have a look at the script in more details (this is the simplified script without all the shiny terminal colors and logging output). You should create a project in the Google Cloud Console, and note its project ID, as we’ll reuse it for storing our audio file.
#!/bin/bash
# create an API key to access the Speech and NL APIs
# https://support.google.com/cloud/answer/6158862?hl=en
export API_KEY=YOUR API KEY HERE
# create a Google Custom Search and retrieve its id
export CS_ID=THE ID OF YOUR GOOGLE CUSTOM SEARCH
# to use sox for recording audio, you can install it with:
# brew install sox --with-lame --with-flac --with-libvorbis
sox -d -r 16k -c 1 query.flac
# once the recording is over, hit CTRL-C to stop
# upload the audio file to Google Cloud Storage with the gsutil command
# see the documentation for installing it, as well as the gcloud CLI
# https://cloud.google.com/storage/docs/gsutil_install
# https://cloud.google.com/sdk/docs/
gsutil copy -a public-read query.flac gs://devoxx-ml-demo.appspot.com/query.flac
# call the Speech API with the template request saved in speech-request.json:
# {
# "config": {
# "encoding":"FLAC",
# "sample_rate": 16000,
# "language_code": "en-US"
# },
# "audio": {
# "uri":"gs://YOUR-PROJECT-ID-HERE.appspot.com/query.flac"
# }
#}
curl -s -X POST -H "Content-Type: application/json" --data-binary @speech-request.json "https://speech.googleapis.com/v1beta1/speech:syncrecognize?key=${API_KEY}" > speech-output.json
# retrieve the text recognized by the Speech API
# using the jq to just extract the text part
cat speech-output.json | jq -r .results[0].alternatives[0].transcript > text.txt
# prepare a query for the Natural Language API
# replacing the @TEXT@ place holder with the text we got from Speech API;
# the JSON query template looks like this:
# {
# "document": {
# "type": "PLAIN_TEXT",
# "content": "@TEXT@"
# },
# "features": {
# "extractSyntax": true,
# "extractEntities": false,
# "extractDocumentSentiment": false
# }
#}
sed "s/@TEXT@/`cat text.txt`/g" nl-request-template.json > nl-request.json
# call the Natural Language API with our template
curl -s -X POST -H "Content-Type: application/json" --data-binary @nl-request.json https://language.googleapis.com/v1beta1/documents:annotateText?key=${API_KEY} > nl-output.json
# retrieve all the analyzed words from the NL call results
cat nl-output.json | jq -r .tokens[].lemma > lemmas.txt
# only keep the words after the "about" word which refer to the topic searched for
sed -n '/about/,$p' lemmas.txt | tail -n +2 > keywords.txt
# join the words together to pass them to the search engine
cat keywords.txt | tr '\n' '+' > encoded-keywords.txt
# call the Google Custom Search engine, with the topic search query
# and use jq again to filter only the title of the first search result
# (the page covering the talk usually comes first)
curl -s "https://www.googleapis.com/customsearch/v1?key=$API_KEY&cx=$CS_ID&q=`cat encoded-keywords.txt`" | jq .items[0].title
And voila, we have our conference assistant on the command-line! We combined the Speech API to recognize the voice and extract the text corresponding to the query audio, we analyze this text with the Natural Language API, and we use a few handy command-line tools to do the glue.