New Features in the Google Cloud Natural Language Api Thanks to Your Feedback
https://cloud.google.com/blog/products/gcp/new-features-in-the-google-cloud-natural-language-api-thanks-to-your-feedback/
The GA release of Cloud Natural Language API is easier to use, better at recognizing language nuances and adds additional support for Spanish and Japanese
Earlier in November, we announced general availability for the Cloud Natural Language API and highlighted the key new improvements. This launch included many additions to the API like expanded entity recognition, granular sentiment analysis with expanded language support, improved syntax analysis with additional morphologies and more.
Many of these improvements were the result of feedback from beta users, so thank you for your contributions! But concretely, what do these updates mean? Let’s take a closer look.
Granular sentiment analysis
When analyzing the sentiment of the White House speeches, we were interested in the flow of phrases and how sentiment evolves throughout the text. We were looking at each sentence one at a time, making an API call for every sentence! This is obviously not the most efficient way to analyze a long document.
With this new version of the Cloud Natural Language API, you still have the overall sentiment of the article but you also get individual, per-sentence sentiment with a score (ranging between -1 and +1, from negative to positive) and a magnitude. In cases where a sentence or document’s score is close to zero, it’s helpful to look at magnitude to distinguish between neutral or mixed text. Text with both positive and negative sentiment will have a higher magnitude, whereas text with neutral sentiment will have a magnitude closer to zero. Unlike score, magnitude is not normalized and shows the total amount of sentiment in the text.
Let’s look at a few sentences from Mrs. Obama’s address at the National Arts and Humanities Youth Program Awards:
This kind of work is hard. Too often it’s thankless. But you all do it because you see firsthand the transformative impact that the arts can have on our young people. And we’re grateful to you all for doing this kind of work.
In addition to an overall score of 0.3 and magnitude of 1.7, we also get the sentiment for each sentence:
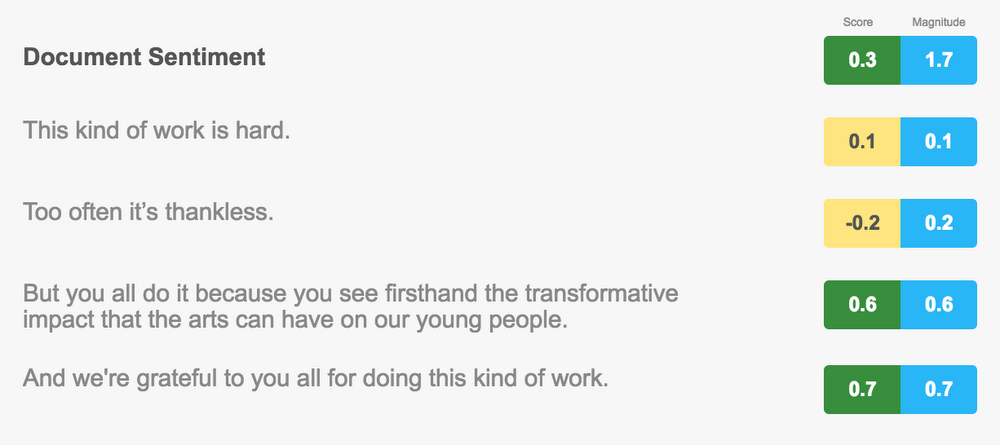
Notice how the first sentences establish a somewhat difficult context with neutral or slightly negative sentiment. The following sentences are much more positive, and with stronger magnitude. Sentiment analysis helps us understand how sentiment evolves throughout our document.
With fine-grained per-sentence, sentiment analysis, there’s no need to fire multiple calls to the API — just one per document. A large document can have widely varying sentiment, and a more detailed analysis of the tone at a granular level provides more insight into the understanding of the text.
For a deep dive on using sentiment analysis on tweets, take a look at this blog post about analyzing tweets during the 2016 Rio Olympics. Y Media Labs also published a post recently about using the Cloud Natural Language API to compare the sentiment of ridesharing apps.
Expanded entity recognition
In a sentence like “Adele is an English singer-songwriter,” we naturally know that “Adele” and the “English singer-songwriter” are the one and only person. But it’s not necessarily that trivial for computers. Let’s see what the API tells us, when you try it online:
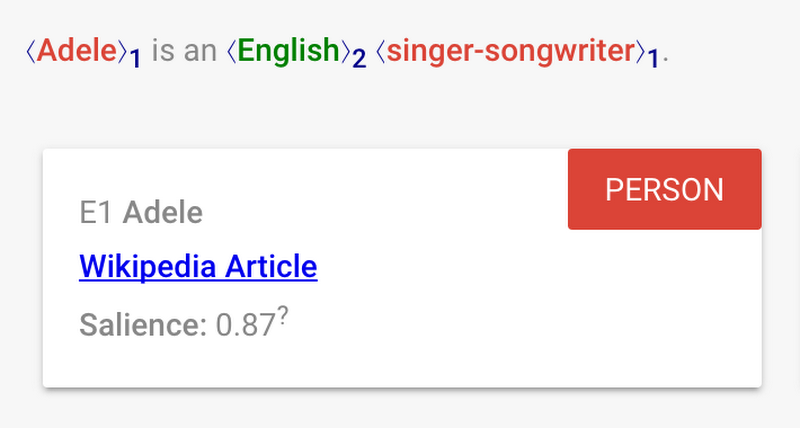
Not only does the API point you at the Wikipedia entry about Adele, but it also managed to figure out that both the name and description were about the same person (i.e., entity #1 in red).
If you look at the JSON payload returned:
"entities": [
{
"name": "Adele",
"type": "PERSON",
"metadata": {
"mid": "/m/02z4b_8",
"wikipedia_url": "http://en.wikipedia.org/wiki/Adele"
},
"salience": 0.86802435,
"mentions": [
{
"text": {
"content": "Adele",
"beginOffset": 0
},
"type": "PROPER"
},
{
"text": {
"content": "singer-songwriter",
"beginOffset": 20
},
"type": "COMMON"
}
]
}...
Only one entity is returned, but two mentions are given, including the offset where those two mentions appear. The first mention is a proper name, while the second one is just a common name, but still referring to Adele.
Understanding how the various elements of a sentence refer to others is a powerful capability that can now be practiced by software, not just by humans!
Improved syntax analysis
Interested in getting into the nitty-gritty linguistic details of a piece of text? The Cloud Natural Language API’s syntax-analysis response now includes much more syntactic data for each word. Let’s take this sentence as an example:
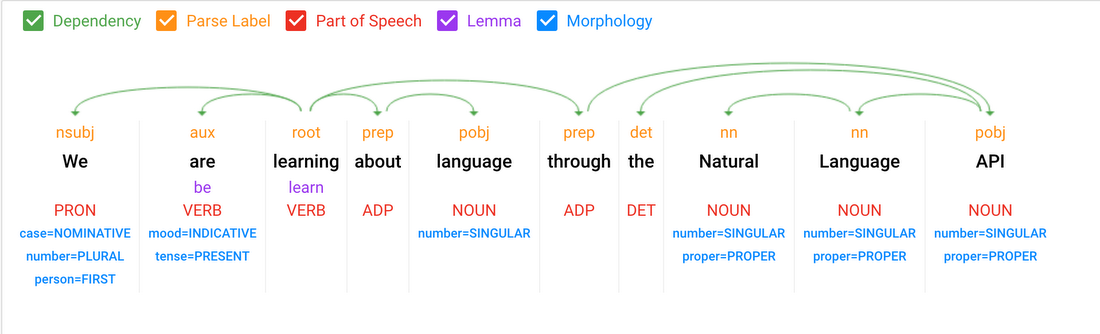
In addition to getting the dependency (the arrows in the image above) and part of speech tag for each word, the API returns all sorts of other linguistic info.
Here’s the JSON response we get for the word “We” in the above sentence:
{
"text": {
"content": "We",
"beginOffset": 0
},
"partOfSpeech": {
"tag": "PRON",
"case": "NOMINATIVE",
"number": "PLURAL",
"person": "FIRST",
...
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "NSUBJ"
},
"lemma": "We"
}
Let’s dive deeper into the new values. The token JSON response tells us whether the word is plural or not, indicated by the number value. person tells us that this word is written in the first person. case is a bit more complex, and reveals the function performed by nouns or pronouns in a sentence. “We” is nominative because it’s the subject of the verb “are.” If the subjects and verbs in the sentence were reversed (“They taught us”), “us” would return a value of ACCUSATIVE for case.
The word “are” in the sentence above returns two more new values:
{
"mood": "INDICATIVE",
"tense": "PRESENT"
}
mood, not to be confused with sentiment, refers to the modality of the word or the way in which something is done. The indicative modality in this example shows that this is a statement of fact. Imperative modality, in contrast, describes direct commands. In the sentence “Go learn the Natural Language API,” the word “Go” is imperative. This mood value is useful if you’re building a bot or automated tool, where you need to understand if something is a statement or command.
The word “linguistics” in our example also returns a number value of SINGULAR. Even though “linguistics” could be misinterpreted as a plural form of the word linguistic since it ends in “s,” the API is able to pick up contextual clues that “linguistics” here refers to the singular field of linguistics. Finally, the API is able to identify “Natural Language API” as a proper noun.
Improved support for Spanish and Japanese
The updated API now supports sentiment and additional morphology analysis for Spanish and Japanese. Let’s see a couple examples in these languages!
In his poem “Canción otoñal” from Libro de Poemas, the Spanish poet Federico García Lorca writes: La luz me troncha las alas y el dolor de mi tristeza (which translates to “The light shatters my wings and the pain of my sadness.”) If you look at the verb “troncha” (to shatter), the API gives some interesting details:
"partOfSpeech": {
"tag": "VERB",
"aspect": "IMPERFECTIVE",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"proper": "NOT_PROPER",
"tense": "PRESENT",
"voice": "ACTIVE",
...
}
The verb has an “imperfective” aspect, an “indicative” mood, is “singular,” at the “third person” and uses an “active” voice at the “present” tense. The API knows the Spanish grammar perhaps better than you can remember it!
The Cloud Natural Language API is just as happy to analyze your Japanese content. Let’s look at this sentence, which means “We are learning more about language through the NL API.” What does its structure looks like?
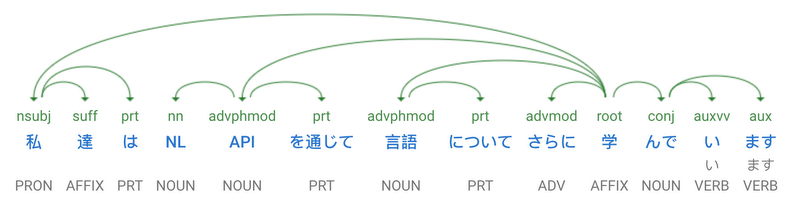
Try it in the browser!
The new Cloud Natural Language API features provide:
- Granular sentiment analysis: you get sentiment data for each sentence in your document so you don’t need an API call for each sentence. This makes your code more streamlined without requiring costly round-trips to our servers.
- Additional morphology details: the subtleties of the language are clearly depicted with more detailed parts of speech tags for each token.
- Improved entity recognition: the API now recognizes multiple mentions of the same entity.
- Multi-language support: the API added sentiment analysis for Spanish and Japanese along with new morphology details for both languages.
Head over to the Google Cloud Natural Language API page and try these enhancements to the API for yourself in your browser. You’ll be able to look-up entities, discover the sentiment of the text and understand the fine-grained details of the structure of the text with hierarchical graphics. You’ll notice in the syntax visualization that some words are blue; hover over these words for more morphology details.
Next steps
Want to start using the Cloud Natural Language API in your own apps? Try these next steps:
- Follow the quickstart guide
- Let us know what you think in the comments
- Use the google-cloud-nl tag on Stack Overflow
- Learn more about other Cloud APIs for machine learning
- Get trained on Cloud ML at a Next ‘17 technical bootcamp on March 6-7 in San Francisco
We’re excited to see what you build!