Putting a Groovy Twist on Cloud Vision
https://cloud.google.com/blog/products/ai-machine-learning/putting-a-groovy-twist-on-cloud-vision
Powerful machine learning APIs are at your fingertips if you’re developing with Google Cloud Platform, as client libraries are available for various programming languages. Today, we’re investigating the Cloud Vision API and its Java SDK, using the Apache Groovy programming language—a multi-faceted language for the Java platform that aims to improve developer productivity thanks to a concise, familiar and easy to learn syntax.
At GR8Conf Europe, in Denmark, the conference dedicated to the Apache Groovy ecosystem, I spoke about the machine learning APIs provided by Google Cloud Platform: Vision, Natural Language, Translate, and Speech (both recognition and synthesis). Since it’s a groovy conference, we presented samples and demos using a pretty Groovy language. I wanted to share the underlying examples with a wider audience, so here’s the first of a series of blog posts covering the demos I presented. I’ll start with the Google Cloud Vision API, and I will cover the other APIs in future posts.
Google Cloud Vision API lets you:
- Get labels of objects and places from your pictures
- Detect faces, with precise location of facial features
- Determine if the picture is a particular landmark
- Check for inappropriate content
- Obtain some image attributes information
- Find out if the picture is already available elsewhere on the internet
- Detect brand logos
- Extract text that appears in your images (OCR)
You can try out those features online directly at the Cloud Vision API product page.
Here’s the output of a visibly egocentric example that I tried on the product page:
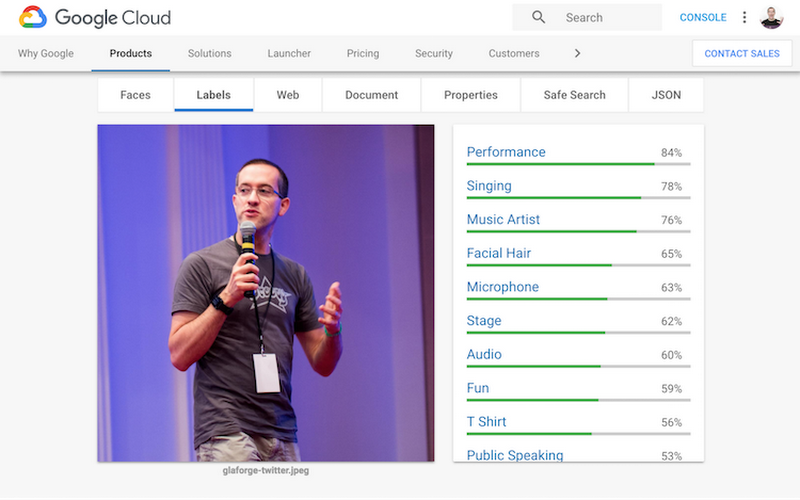
In this first installment, I focus on two aspects: labels and OCR. But before diving in, I want to illustrate some of the use cases that all of the Vision API features enable, when you want to enhance your apps by integrating the Vision API.
Label detection
What’s in the picture? That’s what label detection is all about. So for example, if you’re showing a picture from your vacation of your family and your dog on the beach, you might get labels like People, Beach, Photograph, Vacation, Fun, Sea, Sky, Sand, Tourism, Summer, Shore, Ocean, Leisure, Coast, Girl, Happiness, Travel, Recreation, Friendship, and Family. Those labels are also accompanied by a percentage confidence score.
Example use cases:
- If you run a photography website, you might want to let your users search for particular pictures on specific topics. Rather than having someone manually label each and every picture uploaded, you can store labels generated by the API as keywords for your search engine.
- If you’re building the next friend-finder app for animals, perhaps you want to check that the picture indeed contains a dog. Again, labels will help to tell you if that’s the case without manually checking each submitted image.
- If you need to find pictures that match a certain theme, you can use the labels to help with automatic categorization.
Face detection
The Cloud Vision API can spot faces in your pictures with great precision: it gives you detailed information about the location of the face (with a bounding box), plus the position of each eye, eyebrow, and ear, as well as the nose, lips, mouth, and chin. It also tells you how the face is tilted, and even at what angle!
You can also learn about the sentiment of the person’s expression: joy, sorrow, anger, or surprise, for example. In addition, you’re told if the face is exposed, blurred, or is sporting headwear.
Example use cases:
- You are building a light-hearted app in which users add a mustache or silly hat to uploaded pictures, you now know how to initially position and size the added objects.
- If you want to know (or estimate) the number of attendees in a meeting or presentation at a conference, you can use the API to provide a count of the number of faces in the picture.
Landmark detection
For pictures of famous landmarks, like say, the Eiffel Tower, Buckingham Palace, the Statue of Liberty, or the Golden Gate bridge, the API will tell you which landmark it recognized, and will even give you the GPS location coordinates.
Example use cases:
- If you want users of your app or site to upload only pictures of a particular location, you could use those coordinates (provided in latitude and longitude) to automatically check that the place photographed is within the right geo-fenced bounding box.
- If you want to automatically show pictures on a map in your app, you could take advantage of the GPS coordinates, or automatically enrich tourism websites with pictures from the visitors of specific locales.
Inappropriate content detection
Vision API gives you a confidence percentage about different types of potentially inappropriate content in images, including adult content, depictions of violence, medical content (such as surgical procedures or MRIs), and spoofed pictures (with user-added text and marks).
Example use case:
- If you want to avoid the unwelcome surprise of inappropriate user-generated content showing up in your site or app, you can use this capability to filter images automatically.
Image attributes and web annotations
Pictures all have dominant colors, and you can use the Vision API get a sense of which colors are represented in your image and in which proportion. The Cloud Vision API gives you a palette of colors corresponding to your picture.
In addition to color information, it also suggests possible crop hints, so you can crop the picture to different aspect ratios.
You also get information about whether your picture can be found elsewhere on the net, with a list of URLs with matched images as well as full and partial matches.
Beyond the label detection, the API identifies “entities”, returning to you IDs of those entities from the Google Knowledge Graph.
Example use cases:
- If you want to make your app or website responsive, before loading the full images you may want to show colored placeholders for them. You can get that information with the palette information from the API.
- If you’d like to automatically crop pictures while keeping their essential aspects, you can use the crop hints.
- If you allow photographers to upload their pictures on your website and you want to check that no one is stealing pictures and posting them without proper attribution, you can use the API to check if each picture can be found elsewhere on the web.
- For the picture of me in the introduction of this post, Vision API recognized entities like “Guillaume Laforge” (me!), Groovy (the programming language I’ve been working on since 2003), JavaOne (a conference I’ve often spoken at), “Groovy in Action” (the book I’ve co-authored), “Java Champions” (I’ve recently been nominated!), and “Software Developer” (yes, I do code!). Thanks to those entities, you are able to automatically recognize famous people—more than just me!
Brand or logo detection
In addition to text recognition (discussed immediately below), the Vision API tells you if it recognized any logos or brands.
Example use case:
- If you want your company’s brand or products to be displayed on supermarket shelves, you might have people take pictures of those shelves and confirm automatically that your logo is being displayed.
OCR or text recognition
With OCR text detection, you can find text that is displayed in your pictures. Not only does the API gives you the raw text and automatically detects the locale, but you also get all the bounding boxes for the recognized words, as well as a kind of document format, showing the hierarchy of the various blocks of text that appear.
Example use case:
- When you want to automatically scan expense receipts, enter text rapidly from pictures, or tackle any of the usual use cases for OCR, you can use the API to find and extract any text identified within.
Time to get Groovy!
Now that I’ve provided lots of use cases for where and when you may want to use Vision API, it’s time to look at some code, right? So as I said, in this post I’ll highlight just two features: label detection and text detection.
Using the Apache Groovy programming language, I will illustrate two approaches: the first one uses a REST client library like groovy-wslite, and the second one uses the Java client library provided for the API.
Prerequisites
In order to use Vision API, you’ll need to have an account on Google Cloud Platform (GCP). You can benefit from the $300 free trial credits, as well as free quotas. For instance, for Vision API, without even consuming your credits, you can make 1000 calls for free every month. You can also take a look at the API’s pricing details, once you exceed the quota or your credits.
Briefly, if you’re not already using GCP or still don’t have an account, please register and create one.
Once you’ve set up your GCP account, create a cloud project and enable access to Vision API for the project. That’s it—now you’re ready to follow the steps detailed below.
Note that after you have enabled the API, you still need to authenticate your client to use the service. There are different possibilities here. In the OCR example, I call the REST API and use an API key passed as a query parameter. In the label detection sample, I use a service account with application default credentials. You can learn more about those approaches in the authentication documentation.
Okay, let’s get started!
OCR using the Vision REST endpoint
During the spring and summer allergy season, many people are interested in which pollens are likely to trigger their allergies. In France (where I live), we have a website that shows a map of the country, and when you hover over your region, it shows you a picture of the active allergens and their levels. However, this is really just a picture with the names of said allergens. So I decided to extract a list of allergens from this image using the Vision API’s OCR method:
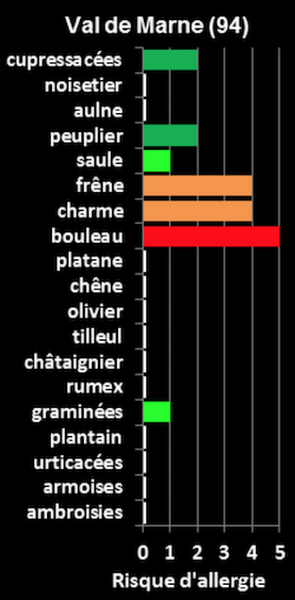
In Apache Groovy, when calling REST APIs, I often use the groovy-wslite library. But there are other similar great libraries like HTTPBuilder-NG, which offer similar capabilities via a nice syntax too.
To start, let’s grab the REST client library and instantiate it:
@Grab('com.github.groovy-wslite:groovy-wslite:1.1.2')import wslite.rest.*
def client = new RESTClient('https://vision.googleapis.com/v1/')
Here’s the URL of the picture with the text I’m interested in:
def imgUrl = "http://internationalragweedsociety.org/vigilance/d%2094.gif"
def API_KEY = 'REPLACE_ME_WITH_REAL_API_KEY'
Be sure to change this dummy text for the API key with a proper API key that you can generate from the “APIs & services > Credentials” section in the cloud console, as explained here.
Next, I’m going to send a post request to the /images:annotate path with the API key as a query parameter. My request is in JSON, and I’m using Groovy’s nice list and maps syntax to represent that JSON request, providing the image URL and the feature I want to use (i.e. text detection):
def response = client.post(path: '/images:annotate', query: [key: API_KEY]) {
type ContentType.JSON
json "requests": [
[
"image": [
"source": [
"imageUri": imgUrl
]
],
"features": [
[
"type": "TEXT_DETECTION"
]
]
]
]
}
This corresponds to the following JSON payload:
{ "requests": [{
"image": {
"source": { "imageUri": imgUrl }
},
"features": [
{ "type": "TEXT_DETECTION" }
]}
]}
Thanks to Apache Groovy’s flexible nature, it’s then easy to go through the returned JSON payload to get the list and println all the text annotations and their descriptions (which correspond to the recognized text):
response.json.responses[0].textAnnotations.description.each { println it }
In spite of the low quality of the image and some odd font kerning, the API was able to find allergens like “châtaignier” (with the correct circumflex accent) and “urticacées” (acute accent). On the allergen “cupressacées,” the diacritical mark was missed though, and a space is intertwined, but the font seems to be adding extra space between some letters.
Label detection with the Java client library
For my second sample, I was inspired by my visit to Copenhagen for GR8Conf Europe. I decided to see what labels the API would return for a typical picture of the lovely colorful facades of the Nyhavn harbor.

Let’s grab the Java client library for the vision API:
@Grab('com.google.cloud:google-cloud-vision:1.24.1')
import com.google.cloud.vision.v1.*
import com.google.protobuf.*
Here’s the URL of the picture:
def imgUrl =
"https://upload.wikimedia.org/wikipedia/commons/3/39/Nyhavn_MichaD.jpg"
.toURL()
Now, let’s instantiate the ImageAnnotatorClient class. It’s a Closeable object, so we can use Groovy’s withCloseable{} method:
ImageAnnotatorClient.create().withCloseable { vision ->
We need the bytes of the picture, which we obtain via the .bytes shortcut, and we create a ByteString object from the protobuf library used by the Vision API:
def imgBytes = ByteString.copyFrom(imgUrl.bytes)
To create the request with the AnnotateImageRequest builder, we can employ the Groovy tap{} method to simplify usage of the builder design pattern:
def request = AnnotateImageRequest.newBuilder().tap {
addFeatures Feature.newBuilder()
.setType(Feature.Type.LABEL_DETECTION)
.build()
setImage Image.newBuilder()
.setContent(imgBytes)
.build()
}.build()
In that request, we ask for the label detection feature and pass the image bytes. Next, we call the API with our request and then iterate over the resulting label annotations and their confidence score:
vision.batchAnnotateImages([request]).responsesList.each { res ->
if (res.hasError()) println "Error: ${res.error.message}"
res.labelAnnotationsList.each { annotation ->
println "${annotation.description.padLeft(20)} (${annotation.score})"
}
}
The labels found (and their confidence) are as follows:
waterway (0.97506875)
water transportation (0.9240114)
town (0.9142202)
canal (0.8753313)
city (0.86910504)
water (0.82833123)
harbor (0.82821053)
channel (0.73568773)
sky (0.73083687)
building (0.6117833)
That looks pretty accurate to me!
Conclusion
There are tons of situations where you can benefit from Google Cloud Vision’s simple and effective image analysis and your use of the API becomes even groovier when using the Apache Groovy language! Be sure to try out the API directly from the website with the built-in demo, and get started with our Cloud Vision codelabs.
If you want to go further, I also encourage you to also have a look at the alpha version of Cloud AutoML Vision: you can extend the Vision API by training it on your own picture dataset. By doing so, you can let Cloud Vision recognize particular objects or elements in your photos with finer-grained labels that are specific to your needs.
Upcoming installments in this series will cover natural language understanding (NLU), text translation, speech recognition, and voice synthesis. So stay tuned!