Workflows patterns and best practices — Part 2
https://cloud.google.com/blog/topics/developers-practitioners/workflows-patterns-and-best-practices-part-2
This is part 2 of a three-part series of posts, in which we summarize Workflows and service orchestration patterns. You can apply these patterns to better take advantage of Workflows and service orchestration on Google Cloud.
In the first post, we introduced some general tips and tricks, as well as patterns for event-driven orchestrations, parallel steps, and connectors. This second post covers more advanced patterns.
Let’s dive in!
Design for resiliency with retries and the saga pattern
It’s easy to put together a workflow that chains a series of services, especially if you assume that those services will never fail. This is a common distributed systems fallacy, however, because of course a service will fail at some point. The workflow step calling that service will fail, and then the whole workflow will fail. This is not what you want to see in a resilient architecture. Thankfully, Workflows has building blocks to handle both transient and permanent service failures.
In our post on Implementing the saga pattern in Workflows (and its associated e-commerce sample), we talked about how you can apply the saga pattern and take compensation steps to undo one or more previous steps with the try/except block for permanent service failures.
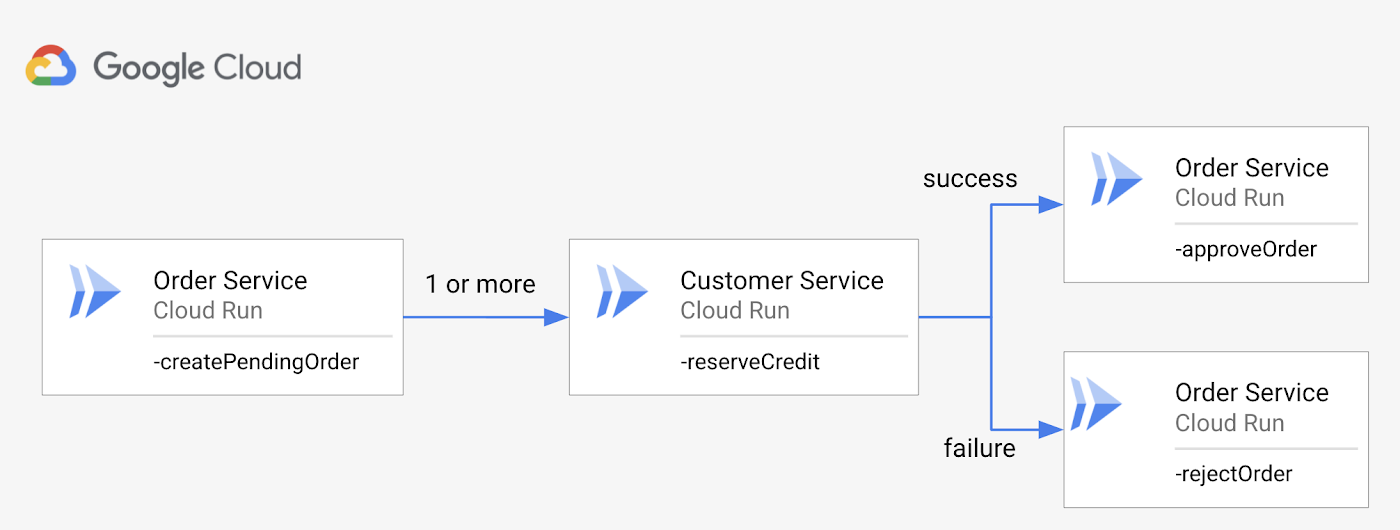
Saga pattern implementation
We also showed how to handle transient service failures by adding the default HTTP retry policy with the try/retry block of Workflows. If you have non-idempotent steps, you need to adjust the retry policy to default_retry_non_idempotent. In most cases, you need a custom retry policy with a longer backoff, because the default one waits at most ~8 seconds. When eventual consistency over a longer time period is more important than fast failure, consider a longer retry policy over several minutes or even hours with a large multiplier is much more likely to succeed during temporary outages.
Don’t take network calls for granted. Make sure you design your orchestration with resiliency in mind using retries and the saga pattern.
Wait for HTTP and event callbacks instead of polling
Sometimes, your orchestration might need to wait for a long-running job or an asynchronous event in another system before it can continue with the rest of the steps. The workflow can ask for that input by polling an endpoint or a queue, but this requires complicated polling logic, wasted polling cycles and most likely higher latency. A better approach is to use Workflows callbacks to wait for HTTP calls or events.
In our Introducing Workflows callbacks post, we showed a workflow that waits for human input for automated machine learning translations. Similarly, the Smarter applications with Document AI, Workflows and Cloud Functions post shows a document processing workflow that waits for human approval of expense reports with a callback.
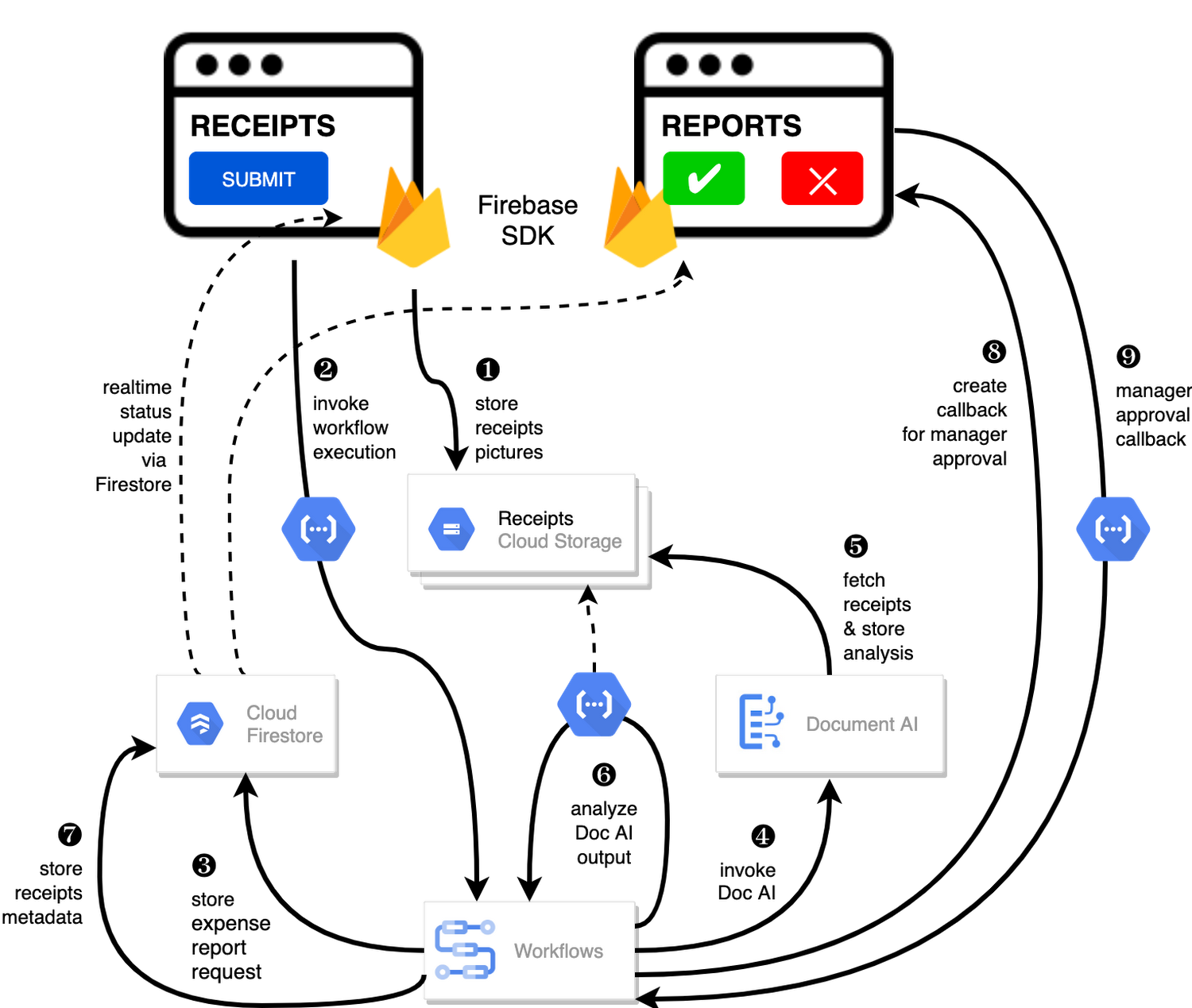
Smarter applications with Document AI, Workflows and Cloud Functions
While both of these posts are focused on waiting for HTTP callbacks, in Creating Workflows that pause and wait for events post, we showed how a workflow can also wait for Pub/Sub and Cloud Storage events. You can even use Google Sheets as a quick and simple frontend for human approvals as we showed in the Workflows that pause and wait for human approvals from Google Sheets post.
When designing a workflow, consider waiting for HTTP calls and events, rather than polling.
Orchestrate long-running batch jobs
If you need to execute long-running jobs, Google Cloud has services such as Batch and Cloud Run jobs that can help. While these services are great for completing long-running jobs on Compute Engine instances and containers, you still need to create and manage the Batch and Cloud Run job service. One pattern that works really well is to use Workflows to manage these services running batch jobs.
In the Taking screenshots of web pages with Cloud Run jobs, Workflows, and Eventarc post, we showed how Cloud Run jobs take screenshots of web pages and Workflows creates and manages parallel Cloud Run jobs tasks. Similarly, in the Batch - prime number generator sample, we showed how to run prime number generator containers in parallel on Compute Engine instances using Google Batch. The lifecycle of the Batch job is managed by Workflows.
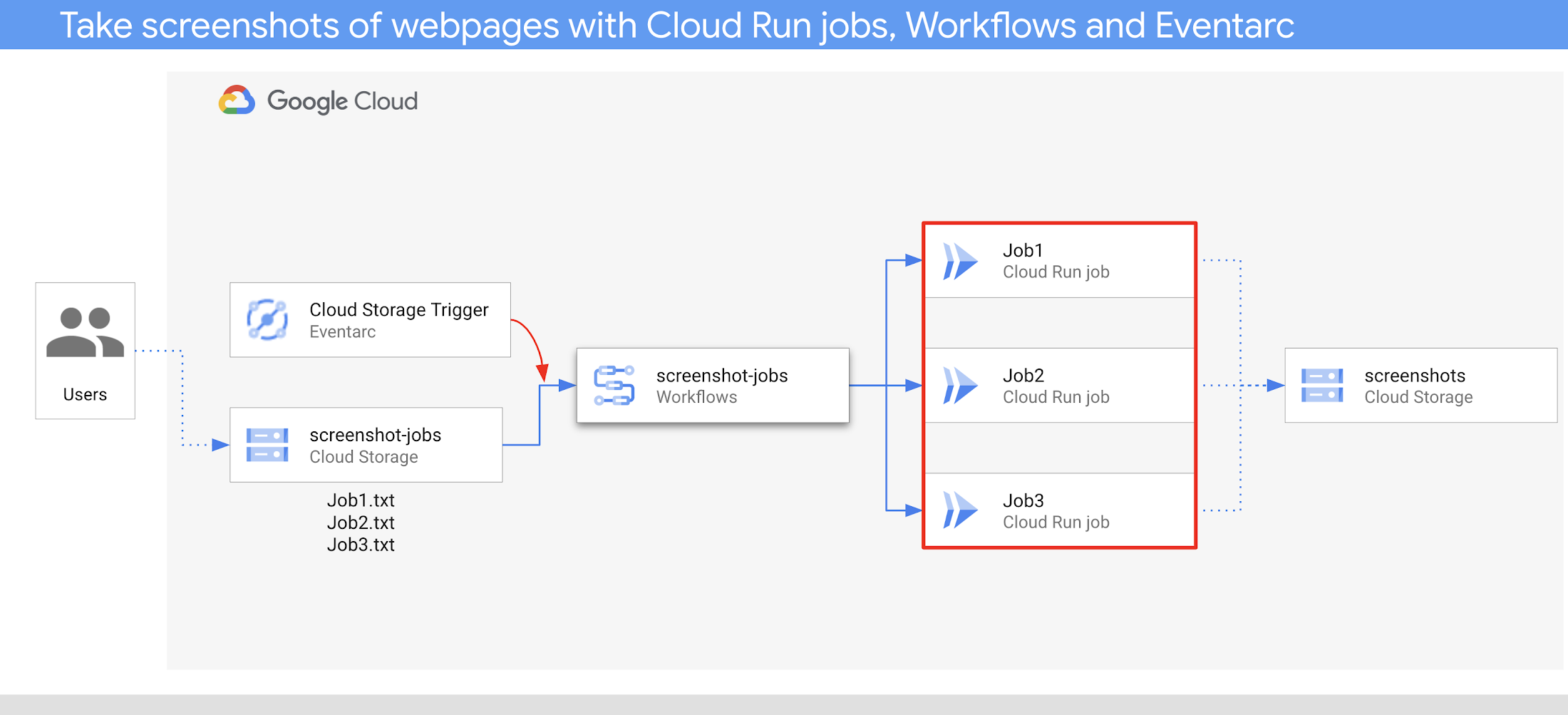
Take screenshots of webpages with Cloud Run jobs, Workflows and Eventarc
Use the right services for long-running batch jobs and use Workflows to manage their life cycles.
Treat serverful workloads as serverless with Workflows
Sometimes, you really need a server due to some serverless limitation. For example, you might need to run on GPUs or execute a long-running process that lasts weeks or months. In those cases, Compute Engine can provide you with customized virtual machines (VM), but you’re stuck with managing those VMs yourself.
In this kind of IT automation scenario, you can use Workflows to create VMs with the customizations you need, run the workloads for however long you need (Workflows executions can last up to one year), and return the result in the end. This pattern enables you to use servers but manage them as if they were serverless services using Workflows.
In our Long-running containers with Workflows and Compute Engine post, we showed how to use Workflows to spin up a VM, start a prime number generator on the VM, run it for however long you want, and return the result.
Next time you need to spin up a VM, treat it like a serverless service with Workflows.
Run command-line tools with Workflows and Cloud Build
We often use command-line tools such as gcloud to manage Google Cloud resources or kubectl to manage Kubernetes clusters. Wouldn’t it be nice if we could call these tools from Workflows and orchestrate management of resources?
In the Executing commands (gcloud, kubectl) from Workflows post, we showed how to use Cloud Build to run these tools and how to create and call that Cloud Build step from Workflows using the Cloud Build connector.
Keep in mind that this pattern is not limited to gcloud and kubectl. Any tool you can run in a container can potentially be a target for Workflows with the help of Cloud Build.
Integrate command-line tools into your workflows when needed by calling a Cloud Build step from Workflows.
This second part series covered a lot of ground, but there’s still more to cover! We’ll wrap up the series in our third and final post, which describes how to manage the lifecycle of workflow definitions and the benefits of using Firestore. Stay tuned! For questions or feedback, feel free to reach out to us on Twitter @meteatamel and @glaforge.