Visualize PaLM-based LLM tokens
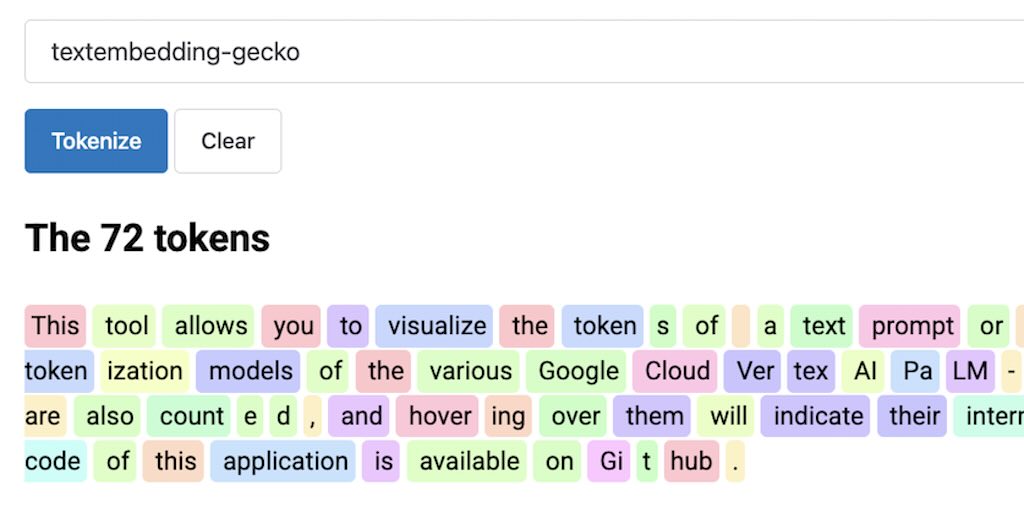
As I was working on tweaking the Vertex AI text embedding model in LangChain4j,
I wanted to better understand how the textembedding-gecko
model
tokenizes the text, in particular when we implement the
Retrieval Augmented Generation approach.
The various PaLM-based models offer a computeTokens endpoint, which returns a list of tokens (encoded in Base 64)
and their respective IDs.
At the time of this writing, there’s no equivalent endpoint for Gemini models.
So I decided to create a small application that lets users:
- input some text,
- select a model,
- calculate the number of tokens,
- and visualize them with some nice pastel colors.
The available PaLM-based models are:
textembedding-geckotextembedding-gecko-multilingualtext-bisontext-unicornchat-bisoncode-geckocode-bisoncodechat-bison
You can try the application online.
And also have a look at the source code on Github. It’s a Micronaut application. I serve the static assets as explained in my recent article. I deployed the application on Google Cloud Run, the easiest way to deploy a container, and let it auto-scale for you. I did a source based deployment, as explained at the bottom here.
And voilà I can visualize my LLM tokens!