Analyzing trends and topics from Bluesky's Firehose with generative AI

First article of the year, so let me start by wishing you all, my dear readers, a very happy new year! And what is the subject of this new piece of content? For a while, I’ve been interested in analyzing trends and topics in social media streams. I recently joined Bluesky (you can follow me at @glaforge.dev), and contrarily to X, it’s possible to access its Firehose (the stream of all the messages sent by its users) pretty easily, and even for free. So let’s see what we can learn from the firehose!
Without further ado, here’s the end goal!

Bluesky’s Firehose — a stream of social messages
The underlying protocol used by Bluesky is the AT Protocol. There’s an API to access Bluesky’s streams via this protocol, but it’s a bit cumbersome to use. In order to reduce the quantity of data sent via the AT protocol over its “relay” network, the Bluesky team introduced JetStream, to relay all the messages as well, via WebSockets, in JSON format, for a fraction of the size of the AT protocol payloads. You can also read about how they shrinked the payloads by 99%!
The JetStream Github repository shares the endpoints you can use to access the firehose, and gives some details about the various types of payloads (new messages, likes, shares, etc.) It also mentioned a nice little tool called websocat which is a command line tool to connect to WebSockets — very handy to analyze the payloads.
To better understand the JSON message formats, I used websocat, as well as Simon Willison’s client-side online tool to access the JetStream, and see the flows of messages.
A bird’s eye view of the project
Before diving into the code, and showing how to fetch the Bluesky posts, I’d like to give you a high level overview of what we’re going to implement.
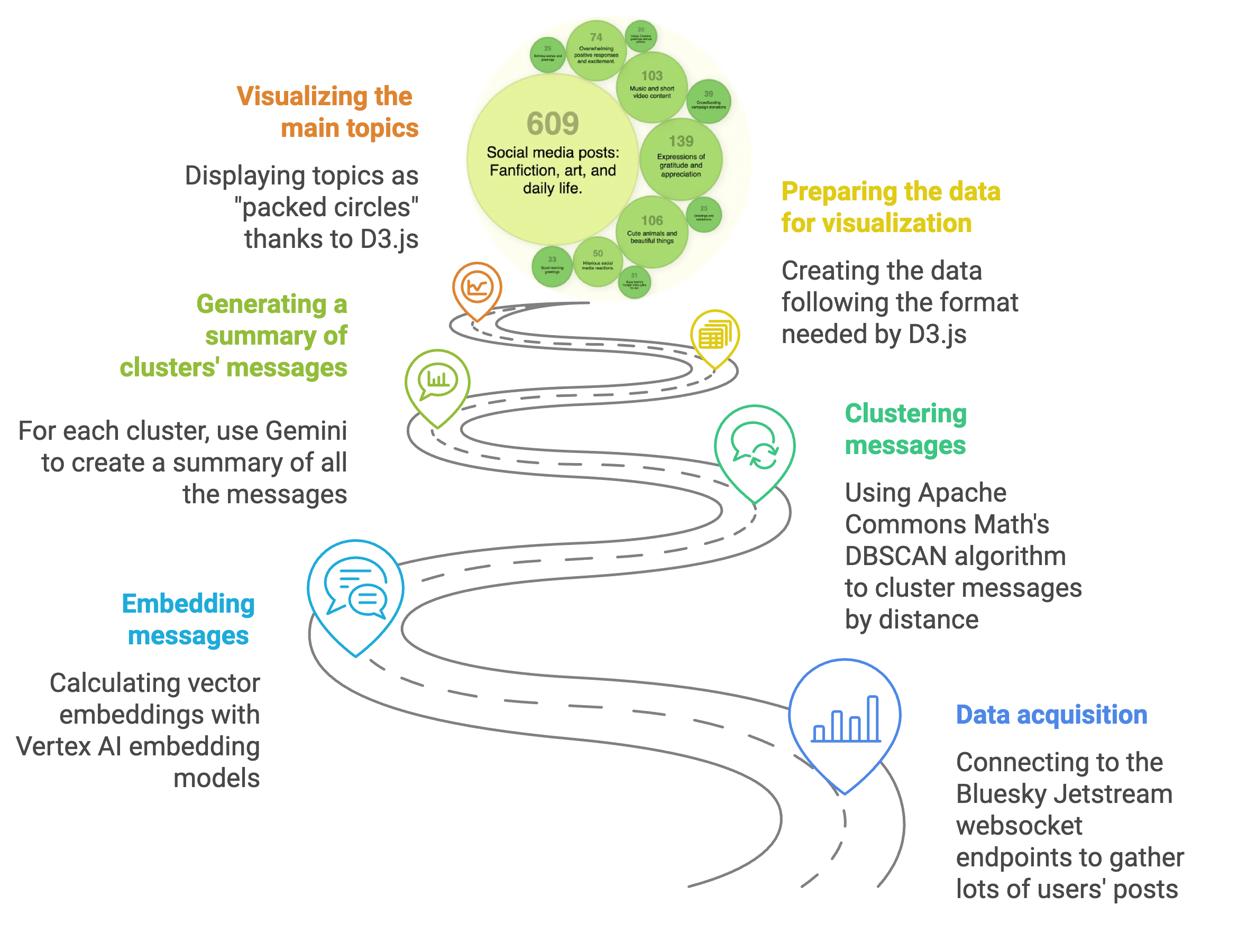
I used Napkin.ai to generate this diagram! Go check out this tool. You can paste your article, and for a given paragraph, it can suggest nice diagrams to represent them.
The key steps towards a topic visualization of the stream are:
- Data acquisition — The first step is to subscribe to the firehose via WebSockets to gather enough data points to make it interesting to extract trends from them.
- Embedding messages — In order to compare users’ posts, the text of the posts should be transformed into vector embeddings via an embedding model, which represents posts into a multidimensional space in which distances can be calculated (text whose vector is closer to another one is usually semantically similar).
- Clustering messages — Now that we have all the vector embeddings, a clustering algorithm is used to create groups of messages that are close to each other in vector space, and form a cluster of data points on the same topic.
- Generating a summary of clusters’ messages — The clustering algorithm grouped messages into different clusters. However, at that point, we don’t know what all those grouped messages are about. That’s where a generative AI model is called to make sense of those messages, to get a short description of them.
- Preparing the data for visualization — Armed with the clusters of posts and their descriptions, the data for the visualization is prepared.
- Visualizing the trends — The last step is to visualize those clusters of messages with a nice visualization. For that purpose, I decided to present the groups of messages as bubbles (the more posts in a bubble, bigger the bubble is).
Let’s get coding!
In the article, I’ll show only key snippets, sometimes simplifying the code a little bit, but you’ll be able to checkout all the code in this Github repository.
As usual, the code will be in Java, and I’m going to use my favorite Generative AI framework: LangChain4j. For the large language model, my choice went for Gemini, and for the embedding model, I’m calculating vectors thanks to Google Cloud Vertex AI embedding models. Clusters of messages will be created with the Apache Commons Math library. The visualization will be implemented in JavaScript with the D3.js library.
Acquiring Bluesky messages via WebSocket
Let’s kick off the project by establishing a real-time connection to the Bluesky firehose using WebSockets, thanks to JDK 11’s HTTP client.
This allows us to receive a constant stream of public posts as they happen.
The liveMessages() method manages the WebSocket connection and filters incoming messages based on language:
httpClient.newWebSocketBuilder().buildAsync(
URI.create(JETSTREAM_WS_ENDPOINT),
new WebSocket.Listener() {
@Override
public CompletionStage<?> onText(WebSocket webSocket,
CharSequence data,
boolean last) {
// ... process incoming message ...
}
});
The onText() method within the WebSocket.Listener is our gateway to the firehose.
Each incoming message, received as a JSON string, needs to be parsed into a usable Java object.
Here’s where Google’s Gson library and Java records come into play.
We’ve defined a set of nested Java records that mirror the Bluesky message structure:
record Message(Commit commit, String did) {
record Commit(Record record, String cid) {
record Record(String text, List<String> langs, Date createdAt) {}
}
}
These records give us a strongly typed way to access message data.
The Message record holds the actual post content (text), a list of languages (langs),
and the creation timestamp (createdAt), nested within Commit and Record records.
We use Gson to deserialize the JSON strings into these records:
Message message = GSON.fromJson(String.valueOf(text), Message.class);
Calculating vector embeddings for all the messages
To analyze the semantic similarity between posts, we convert each post’s text into a numerical vector representation, or embedding. This is achieved using a Vertex AI embedding model, via LangChain4j’s Vertex AI module:
EmbeddingModel embeddingModel = VertexAiEmbeddingModel.builder()
.project(System.getenv("GCP_PROJECT_ID"))
.location(System.getenv("GCP_LOCATION"))
.endpoint(System.getenv("GCP_VERTEXAI_ENDPOINT"))
.modelName("text-embedding-005")
.publisher("google")
.build();
We’re using text-embedding-005 which is a good embedding model and understands multiple spoken languages
(which is important for analyzing posts coming from a hundred different spoken languages or so).
As embedding all messages takes a while, we’re batching the calculation in parallel:
List<TextSegment> allSegments = allMessages.stream()
.map(message -> TextSegment.from(message.commit().record().text()))
.toList();
List<Embedding> allEmbeddings =
IntStream.range(0, numberOfParallelBatches)
.parallel()
.mapToObj(i -> embeddingModel.embedAll(allSegments...)
.flatMap(List::stream)
.toList();
Creating clusters of posts
With embeddings in hand, we can now group similar posts together using the DBSCAN clustering algorithm (Density-based spatial clustering of applications with noise) :
var clusters = new DBSCANClusterer<ClusterableEmbeddedMessage>(
MAXIMUM_NEIGHBORHOOD_RADIUS, MINIMUM_POINTS_PER_CLUSTER)
.cluster(clusterableEmbeddedMessages);
For 10k posts, using a minimum of 10 points per cluster sounds about right. As a rule of thumb, I got good visualizations with one cluster point per 1k messages (ie. 10 points per cluser for 10k messages, 20 points per cluster for 20k messages).
The maximum neighborhood radius at 0.5 also looked like a good value. I tried smaller and bigger values, but either the cluster are too specific and narrow with low values, or too broad and generalist with higher values.
It’s important to check for yourself the hyperparameters of the algorithms you chose for your use case. Some values might be better than others, and they are very much use-case dependant. There’s no magic numbers, you have to experiment to find the right mix for you!
Using a different embedding model (like text-multilingual-embedding-002), reducing the dimensionality to 128 dimensions,
I had to use a max neighborhood radius of 0.2 instead, to get a good number of clusters.
Generating a description for clusters of messages
At this point, we have topic clusters. But they’re just bags of numbers without a real meaning for us, human beings. What we need is a way to make sense of those clusters, to know what topic they cover.
We configure the Vertex AI Gemini model, thanks to LangChain4j’s Gemini module, with a max number of tokens, to avoid situations where a topic description is too long:
ChatLanguageModel chatModel = VertexAiGeminiChatModel.builder()
.project(System.getenv("GCP_PROJECT_ID"))
.location(System.getenv("GCP_LOCATION"))
// .modelName("gemini-2.0-flash-exp")
.modelName("gemini-1.5-flash-002")
.maxOutputTokens(25)
.build();
You can use both the latest Gemini 1.5 Flash, or the new 2.0 Flash experimental model. If you’re hitting quota limits, as 2.0 is currently only in preview, 1.5 will give great results too.
To make the clusters more understandable, we call Gemini to generate a concise summary for each cluster, passing all the messages contained in that cluster:
Response<AiMessage> modelResponse = chatModel.generate(
SystemMessage.from("""
Summarize the following list of social media messages in one
simple description. Don't give a full sentence saying the
social messages are about a topic, just give the topic
directly in 10 words or less, without mentioning the
messages are social media posts or reactions.
"""),
UserMessage.from(appendedMessages)
);
When I was running this code on January 1st, I was seeing topics like New Year's greetings and well wishes or
Happy New Year 2025 wishes and hopeful sentiments for the year.
But some categories of topics often come back, like a big cluster of emojis expressing various expressions,
or people sharing video links on YouTube, or pictures from Instagram.
I also saw some interesting trends as they came up, like weather alerts for snow storms,
or someone famous receiving congratulations for announcing some anniversary.
There are also repeated posts tagging people to request funding for some cause.
Funnily, in the morning, I was often seeing people sharing in how many steps
they solved the Wordle word puzzle!
I filtered the messages to analyze only English messages for the purpose of this demo, but there are a bunch of users setting their language as English, but posting in another language. However it’s not really a problem for Gemini which happily handles more than a hundred spoken languages.
Preparing the data for visualization
The cluster summaries and their sizes (number of posts) are then formatted as JSON data, for ingestion by D3.js:
const data = {
name: "Bluesky topic clusters",
children: [
{name: "Summary of Cluster 1", value: 396},
// ... other clusters
]
};
This JSON structure is ideal for consumption by D3.js, which we’ll use for visualization.
The FirehoseConsumer class writes this JSON data to the newdata.js file,
which is integrated in the static web assets and loaded by D3.
Visualizing the data with D3.js
Finally, the visualisation.js script uses D3.js to create an interactive bubble chart.
Each bubble represents a cluster, with its surface area corresponding to the number of posts in that cluster.
The color of the circles is also dynamically generated:
const colorScale = d3.scaleQuantize()
.domain([0, maxValue])
.range(colorPalette);
//.. later, in the circle
.attr("fill",
d => d.children == null ? colorScale(d.r) : "#fefef0")
What’s more interesting in this part of the project is how the visualization is created. I was inspired by the circle packing visualization seen in this article, which uses D3.js’s circle packing layout method. I borrowed heavily from this example, and tweaked it for my needs, and to my liking.
const pack = d3.pack()
.size([width - margin * 2, height - margin * 2])
.padding(4);
const root = pack(d3.hierarchy(data)
.sum(d => d.value)
.sort((a, b) => b.value - a.value));
The tricky part, as well, was how to render and layout the text of the topics, along with the number of posts per cluster, inside each circle. I got it working by appending a custom div, as a foreign object in the SVG document, and by tweaking the positioning:
node.filter(d => !d.children)
.append("foreignObject")
.attr("x", d => -0.8 * d.r) // center horizontally
.attr("y", d => -1.1*d.r) // center vertically, manually adjusted
.attr("width", d => 1.6 * d.r)
.attr("height", d => 2 * d.r)
.append("xhtml:div")
.classed("foreignDiv", true)
.style("font-size", d => d.r / 5.3 + "px") // dynamic font sizing
.html(d =>
"<span style='font-size: " + (d.r / 2.5) + "px; color: "
+ d3.color(colorScale(d.r)).darker(1) + ";'>"
+ format(d.value)
+ "</span>"
+ d.data.name
+ "<br/>"
);
Lots of hard-coded values to make it look nice!
To put everything together: an HTML file imports D3.js, our newdata.js file containing the cluster definitions,
the visualization.js file creates the bubble chart, plus some CSS in styles.css.
And when running the Java class, the newdata.js is generated and updated in the static web asset folder.
Experiments, and what else to explore
No live demo available
Interesting topic visualizations happen when you have collected enough messages to analyze.
Gathering about 10 thousand posts seemed to offer good results, but in spite of the 10+ million users on Bluesky,
you still need about 4 or 5 minutes to store that many messages.
Without mentioning the time it takes to calculate the embeddings (about 30 seconds in parallel),
and the clustering algorithm (about 1 minute and a half with a runtime complexity of n*log(n)).
So this is not ideal for a real-time analysis of the current trending topics.
That’s why I haven’t posted a demo application online, as it’s too slow to wait for the result to appear on screen.
What might be interesting to explore is somehow a live updating view that would be re-calculated every couple of minutes or so, over a sliding window of messages, but the clustering duration is still a problem. However, it’s also something that could quickly become costly, considering the number of embedding calculations and generative summaries to generate each time.
Different embedding models
Before parallelizing / batching the vector embedding calculations (which still take half a minute), I also tried a non-cloud hosted embedding model, like a quantized version of the all-MiniLM-L6-v2 embedding model, which can run locally without a big GPU. I used it in some other projects with success, but for this clustering exercise, I found the result of poor quality, as if it wasn’t knowledgeable enough to discern different topics.
I paid attention to restricting the messages to only English messages, as I knew that that small model was more at ease with English, but that didn’t really help. Ideally, I’d like to find a fast embedding model with good classification capabilities. But read on, for another idea on speeding up the clustering part of the equation.
Different clustering algorithms
DBSCAN isn’t super fast, with a n*log(n) runtime complexity.
Apache Commons Math also offers a KMeans++ implementation that is faster (with a more linear runtime)
but the k hyperparameter to specify is always giving a fixed number of clusters.
One one hand, it’s nice to have a more predictable visualization (neither too few, nor too many bubbles with small text to display),
on the other hand, the fact the number of clusters si set in stone, leads the clusters to be too generic and too broad,
and there’s always one cluster that contains everything that couldn’t be clustered in meaningful groups.
In spite of its runtime complexity, I like DBSCAN for the fact it creates quite diverse but acurate clusters, as it figures itself how many clusters to create, depending on the various topics it’ll come across.
There’s another library that I’d like to try some day, that’s Smile. It supports even more clustering algorithms than Apache Commons Math.
Something interesting going on for Smile is also its dimensionality reduction algorithms (that they call manifold learning) like t-SNE and UMAP.
Why am I mentioning dimensionality reduction? For one, it’s super handy for visualizing the clusters in 2D or 3D. But another idea I wanted to try was that if the reduction is fast enough, maybe applying the clustering algorithm on lower-dimensioned data would be much faster. The projection (reducing the dimensionality) before clustering approach is also the one this project from HuggingFace followed to cluster the Cosmopedia dataset.
Indeed, Vertex AI embeddings generate vectors of 768 dimensions.
That said, some of the Vertex AI embeddings are Matryoshka embeddings,
so we could also calculate clusters on truncated vectors, without losing too much accuracy, without even doing dimenstionality reduction!
Both text-embedding-005 and text-multilingual-embedding-002 support reducing the vector dimension, so it’s worth trying.
You just need to set outputDimensionality(128) on the embedding model builder to reduce the dimensions down to 128.
Then the clustering time can be go down to 15 seconds instead of 80 seconds like with full 768-dimension vectors.
What else to try?
- In this experiment, I analyzed text, but users post hashtags, pictures, links, on their profiles. It might be interesting to look at what is trending in terms of hashtags, or analyze the sentiment of messages related to such a hashtag.
- Looking at links, maybe it’d be interesting to also see what is shared, which news article is more popular…
- Regarding pictures, we could perhaps see which animals are more trendy? And do some fun analysis of favorite animals in different countries…
- Another interesting analysis could be to cluster user profiles, to find users posting on the same topics.
- I’d like to think more about how to make this application more lively, and make users explore indvidual posts contained in each clusters.
Many more things to try out and explore!
Summary
The generated visualization offers an intuitive and engaging way to explore the trending topics on Bluesky. And generative AI tools like Gemini and Vertex AI are here to help creating such data explorations.
This project combines the power of real-time data streaming, AI-driven analysis, and (not-yet-interactive) visualization to provide a valuable tool for understanding the ever-evolving conversations on Bluesky. It sets the stage for more sophisticated analysis, such as tracking topic evolution over time, sentiment analysis within clusters, and identification of key influencers within specific discussions.
As always, this project also confirmed that Java and LangChain4j are my two best buddies to explore topics with generative AI approaches (no need for Python!) And I was happy to use D3.js again for visualization purposes. It’s not easy to master, but it’s a super powerful library! I’m also glad that Gemini Code Assist helped me work with D3.js, to develop and enhance the visualization.
Finally, of course, the Gemini chat model and Vertex AI embedding model were perfect for the task, giving high quality embedding vectors, and clear synthetic summaries of social media posts.
Don’t hesitate to check out the code and play with this project!