An AI agent to generate short sci-fi stories

This project demonstrates how to build a fully automated short story generator using Java, LangChain4j, Google Cloud’s Gemini and Imagen 3 models, and a serverless deployment on Cloud Run.
Every night at midnight UTC, a new story is created, complete with AI-generated illustrations, and published via Firebase Hosting. So if you want to read a new story every day, head over to:
→ short-ai-story.web.app ←
The code of this agent is available on Github. So don’t hesitate to check out the code:
→ github.com/glaforge/short-genai-stories ←
Let’s have a closer look at the architecture and workflow of this automated storytelling machine.
The agent: the storyteller’s brain
At the heart of the system lies the ExplicitStoryGeneratorAgent, a Java class orchestrating the entire story generation process. This agent follows a clear, multi-step workflow:
- Story conception (Gemini): The agent first calls the Gemini large language model (LLM) to generate the core story elements: a title, five chapters each with title and content.
- Image prompt engineering (Gemini): For each chapter’s content, the agent again leverages Gemini to craft tailored image generation prompts. This ensures that the image prompts are relevant to the specific content of each chapter.
- Illustration generation (Imagen 3): Using the generated prompts, the agent calls Imagen 3 to produce a set of image candidates (four by default) for each chapter.
- Image selection (Gemini, self-reflection): In a unique “self-reflection” step, the agent presents the generated images back to Gemini, asking the LLM to select the image that best visually represents the chapter’s narrative. This crucial step ensures that the illustrations truly complement the story.
- Persistence (Firestore): Once the story, chapter titles, content, and selected images are finalized, the agent stores them in a Firestore database (a NoSQL document database). This makes retrieving complete data relatively straightforward from the web frontend, thanks to the Firebase framework.
For the more visual people among us, this diagram illustrates the steps above:
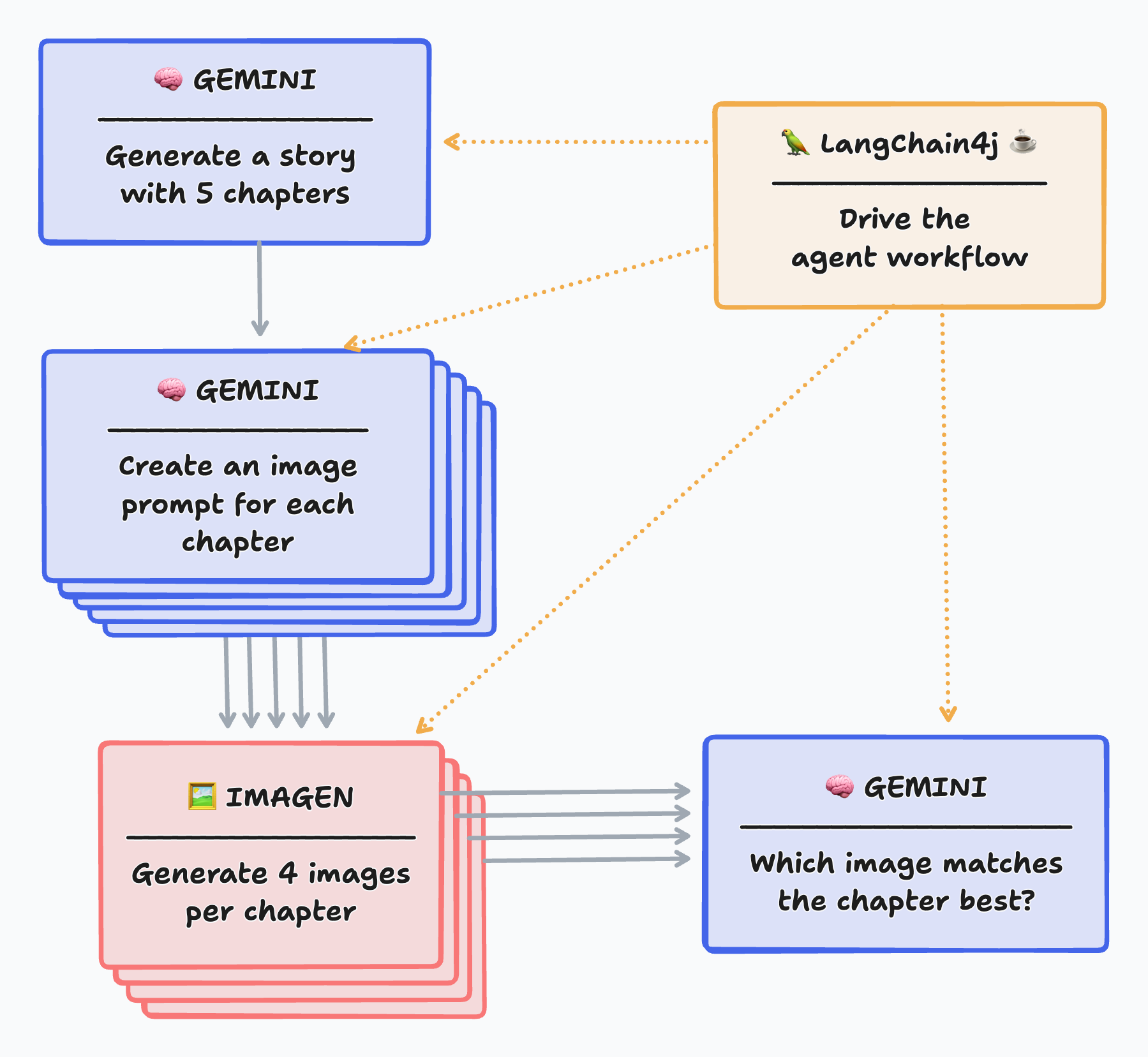
Note: The critique step where Gemini is asked to judge the best image isn’t really necessary, to be honest. Imagen generates images that adhere very much to the given prompt. So either of them would seem suitable to illustrate each chapter. But it was interesting to implement a self-reflection step in this workflow.
Digression: Explicit vs. Autonomous Agent Workflows
This project utilizes an explicit workflow agent, where the story generation process is meticulously defined and controlled by the Java code. This approach contrasts with fully autonomous agents, which rely on the LLM to plan and execute the workflow dynamically.
Let’s explore the key differences and trade-offs between these two approaches:
Explicit workflow agent (code-driven planning):
- Predictable execution: The Java code dictates the exact sequence of steps, ensuring a highly predictable and reliable workflow. Each stage, from story conception to image selection, is explicitly programmed, leaving no room for unexpected deviations.
- Improved performance through parallelization: With explicit control, tasks that can be executed concurrently (such as generating images for different chapters or judging the best image for each chapter) can be easily parallelized. This significantly reduces the overall execution time.
- Easier debugging and maintenance: The clear, structured code makes debugging and maintenance straightforward. The flow of execution is transparent to the developer, and any errors can be readily identified and addressed.
- Limited flexibility: The explicit nature of the workflow could be seen as offering less flexibility. Indeed, the code needs to be updated to handle changes of the workflow. However, it’s not necessarily worse than endlessly tweaking prompts to coerce an LLM to plan correctly the needed workflow changes.
Autonomous agent (LLM-driven planning):
- Dynamic workflow: Autonomous agents use the LLM’s capabilities to plan and execute the workflow. This allows for greater flexibility and adaptability to different story generation requirements. The LLM can theoretically decide which steps to take, in which order, and how many times.
- Potential for hallucinations and errors: Relying on the LLM for planning introduces the risk of hallucinations and incorrect function calls. The LLM might generate nonsensical steps, omit crucial actions, provide incorrect parameters to functions, or execute functions in an illogical order. This can lead to unpredictable results and make it harder to catch potential errors. Even with perfect prompts, LLMs might make mistakes in function calling. This is actually the problem I encountered when trying this approach first.
- Debugging challenges: Debugging autonomous agents can be more complex. The dynamic nature of the workflow makes it harder to trace the execution path and identify the source of errors. Troubleshooting often involves analyzing the logs of the LLM and the tools it requested to call, which can be challenging to interpret at times.
- Less control over execution: With autonomous agents, developers cede some control over the execution flow to the LLM. While this offers flexibility, it also means less fine-grained control over performance optimization. Parallelization opportunities, for example, might not be readily apparent or easily exploitable. Currently, when receiving paralell function call requests, LangChain4j doesn’t yet offer the possibility to request their paralellization.
The autonomous approach would have looked like the following diagram:
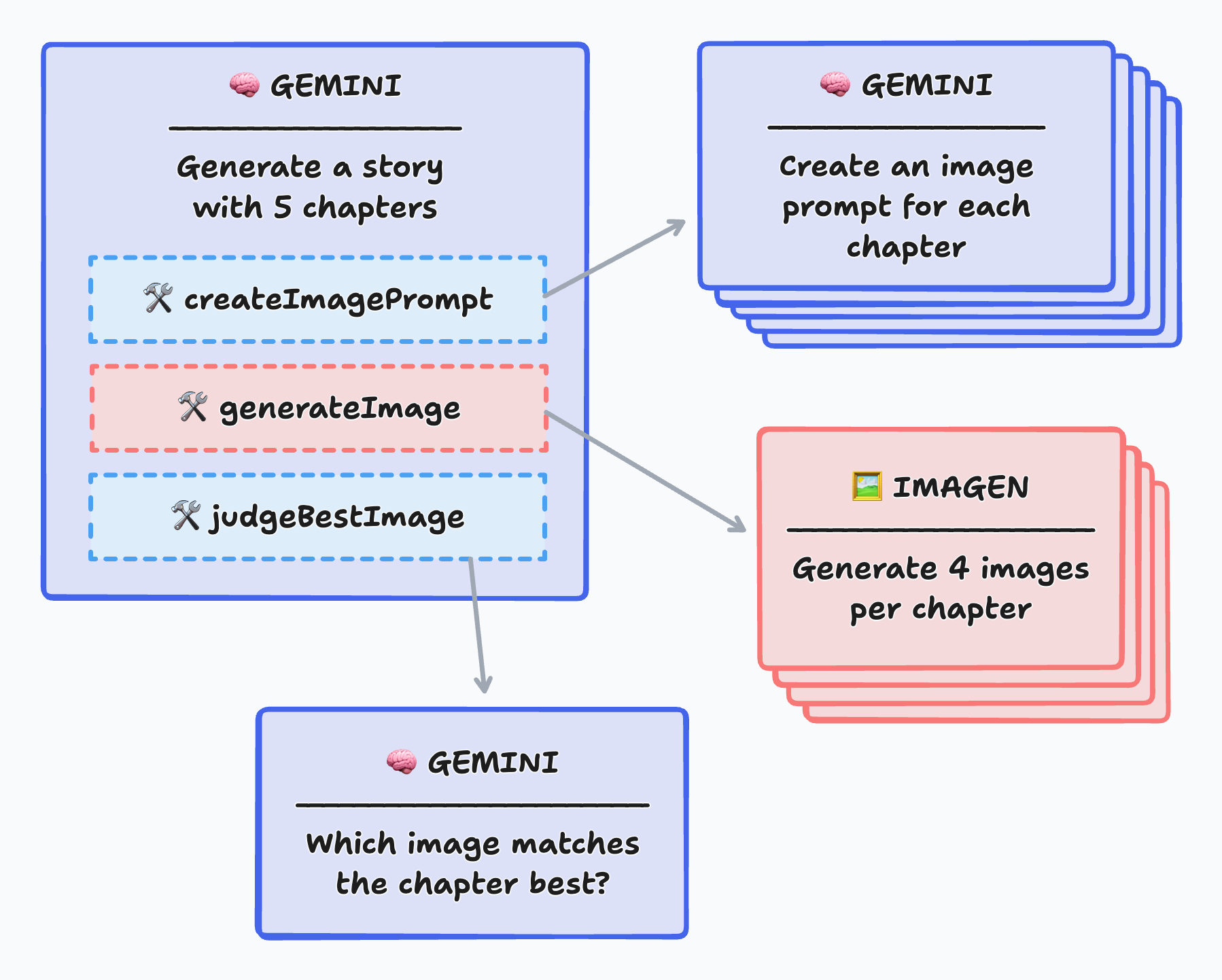
With this approach, the main agent generates the story, then would call first the prompt creation tool, then the generation image tool, and would finish with the tool to pick up the best image. However, in my experience, in spite of a good amount of prompt engineering tweaks, I couldn’t get this to work reliably. I tried with different versions of Gemini (1.5 Flash, 1.5 Pro, and 2.O Flash experimental, from worst to best outcome), but sometimes, for example, it would request to judge images before they had been generated, or the URLs of the images would be hallucinated instead of coming from the outcome of the judge. So I prefered moving to a more explicit approach.
I invite you to read this great article from Anthropic about building effective agents which also makes the distiction between agents (fully autonomous planning agents) and workflows (the more explicit approach with code driving the execution planning). They also recommend to stick to workflows when the logic of the agent is very clear upfront: when you can draw a workflow on a sheet of paper, that’s surely because you do need a workflow.
Choosing the right approach:
The choice between explicit and autonomous workflows depends on the specific requirements of the project. Explicit workflows are best suited for applications where predictability, reliability, and performance are paramount.
Autonomous agents are more appropriate when flexibility, adaptability, and dynamic planning are prioritized, even at the cost of potential errors and increased debugging complexity.
This project prioritizes the former over the latter, which explains why an explicit agent is preferred for this use case. In other words, it’s better to have a predictable solution, which then can be easily parallelized to reduce latency, than a non-predictable solution that is slower.
A closer look at the code
As you’ll be exploring the code base, I’d like to highlight a few points.
The ExplicitStoryGeneratorAgent class uses a structured and predictable approach to orchestrating the LLM. Its core logic resides within the main() method, outlining a clear, step-by-step workflow:
// 1️⃣ let's prepare the story
Story story = prepareStory("a science-fiction novel");
// 2️⃣ iterate over each chapter in parallel
List<Story.Chapter> newChaptersWithImages = story.chapters.stream()
.parallel()
.map(chapter -> {
// 3️⃣ prepare an impage prompt for each chapter
String imagePrompt = prepareImagePromptForChapter(chapter);
// 4️⃣ generate up to 4 images per chapter
List<String> imagesForChapter = generateImages(imagePrompt);
// 5️⃣ judge the best image for this chapter
String bestImage = pickBestImageForChapter(
chapter.chapterContent, imagesForChapter);
return new Story.Chapter(
chapter.chapterTitle,
chapter.chapterContent,
bestImage);
}).toList();
Story newStoryWithImages =
new Story(story.title, newChaptersWithImages);
// 6️⃣ save the story to Firestore
saveToFirestore(newStoryWithImages);
Story generation depends on structured output: The agent uses Gemini to generate the story’s title and five chapters, each with a title and content. Crucially, it leverages Java records and responseSchema to ensure type safety and consistent outputs. You’ll notice the use of @Description annotations to ensure the LLM really understands what each field corresponds to:
record Story(
@Description("The title of the story")
String title,
@Description("The chapters of the story")
List<Chapter> chapters) {
record Chapter(
@Description("The title of the chapter")
String chapterTitle,
@Description("The content of the chapter")
String chapterContent,
@Description("The Google Cloud Storage URI of the image...")
String gcsURI) {
}
}
To configure the model generation to use structured outputs, here’s how the schema of this output is defined:
var chatModel = VertexAiGeminiChatModel.builder()
.project(GCP_PROJECT_ID)
.location(GCP_LOCATION)
.modelName(CHAT_MODEL_NAME)
.temperature(1.5f)
.responseSchema(Schema.newBuilder()
.setType(Type.OBJECT)
.putProperties("title", Schema.newBuilder()
.setDescription("The title of the story")
.setType(Type.STRING)
.build())
.putProperties("chapters", Schema.newBuilder()
.setDescription("The list of 5 chapters")
.setType(Type.ARRAY)
.setItems(Schema.newBuilder()
.setDescription(
"A chapter with a title, and its content")
.setType(Type.OBJECT)
.putProperties("chapterTitle", Schema.newBuilder()
.setType(Type.STRING)
.setDescription("The title of the chapter")
.build())
.putProperties("chapterContent", Schema.newBuilder()
.setType(Type.STRING)
.setDescription("The content of the chapter, " +
"made of 20 sentences")
.build())
.addAllRequired(
List.of("chapterTitle", "chapterContent"))
.build())
.build())
.addAllRequired(List.of("title", "chapters"))
.build())
.build();
It’s possible to simplify the schema creation by taking advantage of a helper class. This schema could have been simplified to:
// ...
.responseSchema(SchemaHelper.fromClass(Story.class))
// ...
To instruct the LLM at each step, I tend to use system instructions for setting the role and goal for the LLM, but I use user messages to give the more variable part, like the chapter’s content, or the image prompt. Here’s an example:
Response<AiMessage> response = chatModel.generate(
SystemMessage.from("""
You are a creative fiction author, and your role is to write stories.
You write a story as requested by the user.
A story always has a title, and is made of 5 long chapters.
Each chapter has a title, is split into paragraphs, \
and is at least 20 sentences long.
"""),
UserMessage.from(storyType)
);
The storyType variable in the user message contains the type of story to generate, like "a science-fiction story".
It’s currently set in stone, but you could parameterize this to generate fantasy novels, love stories, etc.
The self-reflection step, where the LLM judges which is the best illustration for a chapter is taking advantage of Gemini’s multimodal capabilities. Indeed, Gemini receives the instruction of picking the best image out of a few, and it is given the text of the request (and the URLs of the pictures), as well as inline references to those images (ie. the Google Cloud Storage URI, pointing at the location of the pictures). Thus, this is a multimodal request, as both text and images are passed in the prompt:
List<String> imagesForChapter = generateImages(imagePrompt);
String bestImage = pickBestImageForChapter(chapter.chapterContent, imagesForChapter);
// Inside pickBestImageForChapter we have:
List<ChatMessage> messages = new ArrayList<>();
messages.add(SystemMessage.from("...prompt to select best image..."));
messages.add(UserMessage.from("...chapter content..."));
imagesForChapter.forEach(imageUrl -> {
// Send each URL as text and as image to the model
messages.add(UserMessage.from(imageUrl + "\n"));
messages.add(UserMessage.from(ImageContent.from(imageUrl)));
});
Response<AiMessage> response = chatModel.generate(messages);
// ... parse best image from response
Building the application
The project employs a standard Java development workflow using Maven for dependency management and building:
- Dependencies: The
pom.xmlfile defines the project’s dependencies, including LangChain4j (for LLM orchestration), the Google Cloud Firestore library (for data persistence), and Google Cloud’s Gemini and Imagen libraries. - Packaging: The Maven build process packages the application into a JAR, and its dependencies by its side. I followed the approach explained in that article: to build a JAR with its dependencies on the side, instead of a shaded / fat JAR. One benefit I see is that the dependencies are one container layer, while the application itself is another, so it should make Docker building layer faster, as the dependencies don’t change often, and that dependency layer would be cached.
- Containerization (Docker): A
Dockerfileis used to containerize the application. The container image includes the executable JAR and dependencies, as well as the Java runtime environment. I used Azul’s Zulu distroless Java 21 base image. The container is finally built thanks to Cloud Build.
Deployment and automation
To automate story generation and deployment, the project leverages several Google Cloud services:
- Cloud Build: Cloud Build automates the process of building the Docker container image. The provided
justfilecontains commands and recipes to build and submit the container image (I coveredjustin a previous article, a nifty little tool to parameterize and run common commands for the project). I simply followed the tutorial in the Cloud Build documentation to submit a build via the CLI (thegcloudCLI SDK), after having done some IAM setup as explained here to be able to push the built image in Artifact Registry. - Cloud Run jobs: The application runs as a Cloud Run job. Contrary to Cloud Run services, where incoming HTTP requests trigger the service, here, jobs are triggered and run to completion. The Cloud Run job allows for serverless execution of the story generation agent. I followed this guide to create jobs. Don’t forget to set up the required environment variables.
- Cloud Scheduler: Cloud Scheduler triggers the Cloud Run job every day at midnight UTC. This automation ensures that a new story is generated and published daily. To configure this, this page explains how to set scheduled triggers.
- Firebase Hosting: Firebase Hosting serves the static assets of the website (HTML, CSS, JavaScript) that displays the stories. Firebase also provides easy access to the Firestore database where the stories are stored, at the last stage of our agentic workflow.
Further possible improvements
I’m not in the business of selling novels, so I won’t really spend much more time improving this application. However, I noticed a few areas where this project could be improved.
More creativity
When reading the short stories, you’ll notice a certain lack of creativity. Somehow, the stories often happen around the years 2340, the action takes places on Xylos, and some characters appear very frequently, like Aris Thorne. Similarly, some words or concepts appear all the time, like the words echoes, obsidian, crimson, etc. Maybe the model has seen such novels, with such personas, locations, time period, in its training. I’ve seen online some people getting the same kind of stories, and even a book with the same characters or location.
I think it’d be interesting to explore how to make the stories more diverse and varied. For example by adding more steps in the workflow to work on character creation, on different narrative arcs, on environment definitions. For science-ficiton only, there are tons of types of sci-fi stories. My friend, Philippe Charrière, worked on how to generate random RPG character names with LLMs. He shared plenty of ideas on how to guide LLMs to get more creative with personas.
Character definition for illustration consistency
Speaking of character creation, if you look at the illustrations, you’ll see that the characters often don’t have the same style or appearance. Indeed, I don’t give Imagen the whole context of the story when I let Gemini create the image prompts. A possible area of improvement could be to work on proper character definitions (face characteristics, attire, etc.), and ensure that the information is passed through to Imagen. The same would apply for the setting, like the planet, the spaceship details, and more.
Chapter legibility
Each story is split into 5 chapters, of about 20 sentences or so. I tried to make Gemini to generate paragraphs, to improve legibility. However, in spite of a bit of time spent on tweaking the prompts, I failed to coerce it to create paragraphs to delineate the key sections of the chapters. When prompting can’t solve this, an extra LLM call loop can take the chapter’s content and make it more readable.
Conclusion
The key take away of this experimetnation, is that when you can describe your AI agent’s plan of action with an explicit and predictable workflow, you should definitely follow that route, and avoid giving the LLM the freedom to handle the planning alone. LLM autonomous planning works much better in more unpredictable cases, where steps can’t be foreseen. Be sure to use the right approach!
Again, Gemini and Imagen were up to the task for this new project and gave great stories and illustrations, even if the creativity could be improved. And I’ll keep using LangChain4j as my Swiss-army knife for all my Generative AI projects, as it works reliably, and offers rich capabilities.
Knowing that I would build a workflow, I also explored the use of my beloved Google Cloud Workflows which I’ve written a lot about. I’ll likely write another (shorter) article where I’ll show how to create such GenAI workflows with it, stay tuned.
This project was also a good opportunity for me to use Cloud Run jobs. I love Cloud Run for all my serverless, auto-scaled, fully-managed, HTTP services, but I hadn’t used a Cloud Run job so far. For such batch kind of tasks, this is the right tool for the job (pun intended)! There’s also Google Cloud Batch but it’s more for heavier computation kind of workloads.
So what’s next? Checkout the website to read a short story every day, and explore the code base to better understand how stories are baked. If you want to replicate this application, and haven’t yet tried Google Cloud, feel free to use the $300 of credits for new users.