The power of large context windows for your documentation efforts
My colleague Jaana Dogan was pointing at the Anthropic’s MCP (Model Context Protocol) documentation pages which were describing how to build MCP servers and clients. The interesting twist was about preparing the documentation in order to have Claude assist you in building those MCP servers & clients, rather than clearly documenting how to do so.
MCP tutorials are great. There are no tutorials really.
— Jaana Dogan ヤナ ドガン (@rakyll) February 14, 2025
"Copy these resources to Claude, and start asking some questions like..." pic.twitter.com/GG50DMWNLW
No more tutorials:
- You discuss with the reference documentation.
- Your chat with the LLM becomes the tutorial!
LLM-powered documentation chats become your tailored tutorial, for your very own specific need and requirements. Not only LLMs can assist you authoring articles, documentation, reports, but LLMs can craft explanations that help you achieve a particular goal for which there’s not already a tutorial or how-to guide available.
Also, sometimes, you overlook some key paragraph of section when browsing through the documentation, and you miss the key information that would have helped you fix the problem at hand. This happened to me recently while using an Obsidian plugin: I needed to configure the plugin in a certain way, and I had the impression it wasn’t possible, but the plugin author pointed me at the key paragraph that I somehow glanced over. Had I asked the question to an LLM-powered chat that has all the reference documentation in its context, maybe it would have found that paragraph I missed?
Here come the large context window LLMs…
As you may already know, I contribute to the LangChain4j open source project, which provides integrations with various LLMs (like Gemini) or vector databases. I hope to start working on an additional module to integrate the new unified Gemini SDK. The advantage of this new SDK is that you can call both Gemini flavors: the one provided by Google Cloud’s Vertex AI offering, as well as DeepMind’s Google AI version. One SDK to rule them all!
I’m also interested in potentially creating a new vector store module for Google Cloud Firestore, which recently added vector calculation support in its Java client library. It would be neat to be able to use Firestore for RAG (Retrieval Augmented Generation) scenarios, taking advantage of the document database, its filtering capabilities, and its ability to do vector similarity searches.
LangChain4j’s documentation provides some explanations on how to contribute new integrations, but I was interested in trying this approach of chatting with the reference documentation to guide my steps in creating a new LLM module, and a new vector store implementation module.
Fortunately, my favorite large language model, Gemini, has a huge context window of up to 2 million tokens! This should be enough to ingurgitate the whole sources and documentation pages of the project.
Additionally, I discovered gitingest a great online tool that allows you to convert a Github project and all its sources into one gigantic text file… that you can then feed to an LLM. Basically, you take the URL of a Github repository, and you replace the github.com part with gitingest.com. For example, for LangChain4j, the URL becomes: https://gitingest.com/langchain4j/langchain4j. Then, a download button lets you get the whole content of the repository.
The prompt
For this experiment, I didn’t code anything, I simply used Google AI Studio.
I selected Gemini 2.0 Pro experimental:

Then, I loaded the big text file of the LangChain4j project, created by gitingest, and look at the number of tokens:
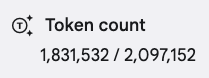
Yes, the whole repository and documentation is almost 2 million tokens long! Only Gemini can ingest that many tokens!
Time to ask my question:
I’d like to create a new language module for LangChain4j. How should I do that? What are the key steps to follow to propose a new model?
The response
Click to reveal the detailed answer
Okay, let’s outline the steps to create a new language model module for LangChain4j and propose its inclusion. Based on the provided file structure, you’ll be focusing on creating a new module similar to the existing ones (e.g., langchain4j-open-ai, langchain4j-ollama, etc.). Here’s a breakdown of the process, referencing the structure you’ve provided:
Key Steps and Considerations
Understand the Abstractions and SPI: LangChain4j, like its Python counterpart, is built around core abstractions. You need to understand these to implement your integration correctly. The core abstractions you must implement are:
ChatLanguageModel/StreamingChatLanguageModel: For conversational models (like ChatGPT, Gemini). ImplementChatLanguageModelfor synchronous responses, andStreamingChatLanguageModelif the model supports streaming responses token by token.LanguageModel/StreamingLanguageModel: For models with a simpler text-in, text-out interface (less common these days).EmbeddingModel: If the model provider offers embedding capabilities.ModerationModel: If the model provider offers content moderation.ScoringModel: If the model provider offers scoring/ranking capabilities.- Builder Factories: You’ll also need to create builder factories (SPIs) for each model type you implement. These are how users will construct your model classes. See examples like
AzureOpenAiChatModelBuilderFactory. These are registered using the Java ServiceLoader mechanism (theMETA-INF/servicesfiles).
Choose a Module Structure (and Repository):
- Community Repo (Preferred for new integrations): Start your integration in the
langchain4j-communityrepository. This is the recommended approach for new contributions. It allows for easier initial review and iteration before considering a move to the corelangchain4jrepository. Clone this repo, don’t fork the mainlangchain4jrepo directly. - Main
langchain4jRepo (For Core Integrations): If your integration is with a very widely used and well-established model provider (like OpenAI, Google, etc.), and you are confident in its stability and long-term maintenance, you might propose it for the main repo. However, start inlangchain4j-communityfirst. - Module Naming: Follow the pattern:
langchain4j-{provider-name}(e.g.,langchain4j-my-llm). - Directory Structure: Create a directory structure mirroring the existing modules (see
langchain4j-open-aiorlangchain4j-ollamaas good examples):langchain4j-{provider-name}/ pom.xml (Your module's Maven build file) src/ main/ java/ dev/ langchain4j/ model/ {providername}/ (e.g., myllm) {ProviderName}ChatModel.java (Your implementation) internal/ (API client and related classes) spi/ (Builder factory for your model) {ProviderName}ChatModelBuilderFactory.java resources/ META-INF/ services/ (Files to register your builder factory, see examples) test/ java/ dev/ langchain4j/ model/ {providername}/ {ProviderName}ChatModelIT.java (Integration tests)
- Community Repo (Preferred for new integrations): Start your integration in the
Implement the API Client:
- Official SDK (Preferred): If the LLM provider has an official Java SDK, use it. This is usually the best approach for stability, performance, and access to all features. See
langchain4j-bedrockfor an example using an official SDK. - HTTP Client (If no SDK): If there’s no official SDK, use the JDK’s built-in
java.net.http.HttpClient(available since Java 11). This minimizes external dependencies. Avoid adding new dependencies unless absolutely necessary. Seehttp-clients/langchain4j-http-client-jdkfor how LangChain4j wraps this. Avoid using the olderokhttp3directly if possible, preferlangchain4j-http-client-jdk(orlangchain4j-http-client-spring-restclientif building a Spring Boot starter). - JSON Handling: Use Jackson for JSON serialization/deserialization, as it’s already a dependency.
- Error Handling: Make sure to handle HTTP errors (non-2xx responses) appropriately. Throw a
dev.langchain4j.exception.HttpExceptionfor these. - Request/Response Logging: Implement logging for requests and responses (see
langchain4j-anthropicfor a complete example). This is very helpful for debugging.
- Official SDK (Preferred): If the LLM provider has an official Java SDK, use it. This is usually the best approach for stability, performance, and access to all features. See
Implement the Model Interface(s):
- Implement
ChatLanguageModel,StreamingChatLanguageModel,EmbeddingModel, etc., as appropriate, based on the provider’s capabilities. - Use the
Builderpattern for your model classes to allow for flexible configuration. - Make sure your implementation handles request/response mapping and error handling correctly.
- Implement
TokenCountEstimatorif possible, so theTokenWindowChatMemorycan calculate the token usage. ImplementDimensionAwareEmbeddingModelto report the output dimension from the embedding model.
- Implement
Write Tests:
- Unit Tests: Create unit tests for any complex logic, utility methods, and request/response mappers.
- Integration Tests (ITs): Create integration tests (e.g.,
MyLlmChatModelIT.java) that interact with the real LLM provider’s API. These are crucial for ensuring your integration works correctly.- Use environment variables (e.g.,
MYLLM_API_KEY) to store API keys and other secrets. Do not hardcode them. - Use
@EnabledIfEnvironmentVariableto skip the tests if the required environment variables are not set. - Extend
AbstractChatModelIT,AbstractStreamingChatModelIT,AbstractEmbeddingModelIT, and/orAbstractScoringModelITto get a set of basic tests. - Test all relevant features of the model (e.g., text generation, streaming, different parameters, tool use, JSON mode).
- Add test for concurrent requests if possible.
- Consider adding a test for the
Tokenizerinterface (see examples inlangchain4j-core). - Add
@RetryingTestif model response is inconsistent
- Use environment variables (e.g.,
Add to BOM (Bill of Materials): Add your new module to
langchain4j-bom/pom.xml. This helps users manage dependencies.Documentation:
- Update
README.md: Add your integration to the list of supported models and embedding stores. - Create Markdown Documentation: Create Markdown files in the
docs/docs/integrations/directory, following the structure of existing integrations. You’ll need:- A main file (e.g.,
my-llm.md). - An entry in
docs/docs/integrations/language-models/index.mdand indocs/sidebars.js. - An entry in
_category_.jsonfiles indocs/docs/integrations/language-modelsanddocs/docs/integrations/embedding-stores
- A main file (e.g.,
- Examples (Highly Recommended): Create a simple example in the
langchain4j-examplesrepository. This is very helpful for users.
- Update
General Guidelines (from CONTRIBUTING.md):
- Java 17: Maintain compatibility with Java 17.
- Minimal Dependencies: Avoid adding new dependencies if possible. If necessary, try to use libraries already present. Run
mvn dependency:analyzeto check. - Backwards Compatibility: Avoid breaking changes. If necessary, deprecate old methods/fields instead of removing them.
- Naming Conventions: Follow existing naming conventions.
- No Lombok: Avoid using Lombok in new code; remove it from existing code if you touch it.
- Javadoc: Add Javadoc where needed.
- Code Style: Run
make lintandmake formatbefore committing. - Large Features: Discuss large features with maintainers (@langchain4j) before implementation.
Open a Pull Request (Draft First):
- Open a draft PR in the
langchain4j-communityrepository. - Fill out all sections of the PR template.
- Once the PR is reviewed and approved, you will be asked to finalize it (add documentation, examples, etc.).
- Open a draft PR in the
Example Code Snippets (Illustrative)
// MyLlmChatModel.java (in the appropriate package)
public class MyLlmChatModel implements ChatLanguageModel {
private final MyLlmClient client; // Your custom client
private final String modelName;
@Builder
public MyLlmChatModel(String baseUrl, String apiKey, String modelName, Duration timeout) {
this.client = new MyLlmClient(baseUrl, apiKey, timeout); // Your custom client
this.modelName = modelName;
}
@Override
public Response<AiMessage> generate(List<ChatMessage> messages) {
// 1. Convert Langchain4j messages to MyLLM's request format
// 2. Call client.chat(...)
// 3. Convert MyLLM's response to LangChain4j's Response<AiMessage>
// 4. Handle errors (throw HttpException)
return null; // TODO: Implement
}
// ... other methods, builder, etc. ...
}
// MyLlmClient.java (in a suitable package, e.g., dev.langchain4j.model.myllm.internal)
class MyLlmClient {
// ... implementation using java.net.http.HttpClient ...
}
// MyLlmChatModelBuilderFactory.java (in a suitable package, e.g., dev.langchain4j.model.myllm.spi)
public class MyLlmChatModelBuilderFactory implements Supplier<MyLlmChatModel.Builder> {
@Override
public MyLlmChatModel.Builder get() {
return MyLlmChatModel.builder();
}
}
// META-INF/services/dev.langchain4j.model.chat.spi.ChatLanguageModelBuilderFactory (resource file)
// Add a line with the fully qualified name of your factory:
// dev.langchain4j.model.myllm.spi.MyLlmChatModelBuilderFactory
Key Points and Common Mistakes
- Thorough Testing: Integration tests are absolutely essential. Test with real API calls.
- Error Handling: Handle HTTP errors (non-2xx responses) from the LLM provider’s API.
- Token Usage: If the LLM provider gives you token usage information, include it in the
Response. - Finish Reason: If the LLM provider gives you a finish reason (e.g., “stop”, “length”), include it in the
Response. - Consistency: Maintain consistency with existing LangChain4j modules in terms of naming, structure, and coding style.
- Documentation: Clear, concise, and accurate documentation is critical. Follow the patterns you see in existing modules.
- SPI Registration: Remember to create the
src/main/resources/META-INF/services/files to register your model implementation as a service.
This comprehensive guide, combined with the provided file structure and examples, should give you a strong foundation for contributing your new language model integration to LangChain4j. Remember to start in the langchain4j-community repository for initial development and review. Good luck!
The verdict
Honestly, this is really good! It follows the advice in the contributing guidelines. But since it has access to the whole code base, it understands pretty well the various steps to follow, the classes to implement, etc.
A few nits though: for example, it confirms we shouldn’t use Lombok for creating builders, but the example code shows a @Builder annotation from Lombok, because it’s still used in several modules. Or there’s this reference to the make tool, although the project doesn’t use it at all. The code suggests implement the generate() methods, but newer models should now implement the new chat() method instead, but Gemini can’t really know about this, as this is fairly new and not many models implement those interfaces for now.
But other than that, it’s excellent!
Gemini created a contributing guide by looking at almost 2 million tokens of code and documentation. But this doesn’t end here, you can continue asking other questions, to get more insight into particular aspects of the development of a new module, and Gemini would continue the discussion, guiding you and helping you in your task. I found that quite impressive.
Let’s continue the conversation with the code base and documentation
As I was interested in creating a new embedding store for Firestore, I then added in the context the documentation of the Java SDK for Firestore. And asked the following question:
I would also like to create a new embedding store for the Google Cloud Firestore database. What are the steps to create a new LangChain4j embedding store module?
Let’s see what it suggested:
Click to reveal the detailed answer
Okay, here’s a breakdown of how to create a new LangChain4j embedding store module for Google Cloud Firestore, along with the key steps and considerations, mirroring the structure of existing modules like langchain4j-milvus.
Project Structure
Your project structure should follow the established pattern. I’ll create a simplified version based on the most relevant parts from the provided file listing. The full structure would be much larger (like the main langchain4j project), but this captures the essentials:
langchain4j/
└── langchain4j-embedding-store-google-firestore/ (or similar name)
├── pom.xml (Your module's Maven build file)
└── src/
└── main/
└── java/
└── dev/
└── langchain4j/
└── store/
└── embedding/
└── google/
└── firestore/
└── GoogleFirestoreEmbeddingStore.java (Main class)
└── (Any other supporting classes, like request/response objects)
└── test/
└── java/
└── dev/
└── langchain4j/
└── store/
└── embedding/
└── google/
└── firestore/
└── GoogleFirestoreEmbeddingStoreIT.java (Integration test)
Steps to Create the Module
Project Setup (Maven Module):
- Create a new directory named
langchain4j-embedding-store-google-firestore(or a similar, descriptive name) within thelangchain4jparent directory. - Create a
pom.xmlfile inside this new directory. This file will define your module as a Maven project and specify its dependencies. Uselangchain4j-milvus/pom.xmlas a guide, but adapt it:- Parent: Set the parent to
langchain4j-parent, as shown in your example. - ArtifactId: Use
langchain4j-embedding-store-google-firestore. - Name and Description: Update these appropriately.
- Dependencies: Include
langchain4j-coreas a compile-time dependency. Add the Google Cloud Firestore Java client library as a dependency:Add any other necessary dependencies, such as logging (SLF4J), Lombok (if desired, but try to avoid in new code), etc. Minimize dependencies as much as possible.<dependency> <groupId>com.google.cloud</groupId> <artifactId>google-cloud-firestore</artifactId> <version>YOUR_VERSION_HERE</version> <!-- Lookup the latest version --> </dependency> - Test Dependencies: Include JUnit, AssertJ, and any mocking libraries (like Mockito) in the
testscope. - Licenses: Ensure your module has the correct Apache 2.0 license information in the POM.
- Parent: Set the parent to
- Create a new directory named
Implement
EmbeddingStore<TextSegment>:- Create
GoogleFirestoreEmbeddingStore.javain thedev.langchain4j.store.embedding.google.firestorepackage. - Implement the
EmbeddingStore<TextSegment>interface fromlangchain4j-core. This is the crucial part. You’ll need to implement the following methods, mapping them to Firestore operations:add(Embedding embedding): Adds a single embedding to the store, generating a unique ID.add(String id, Embedding embedding): Adds an embedding with a specified ID.add(Embedding embedding, TextSegment textSegment): Adds an embedding with associated text and metadata.addAll(List<Embedding> embeddings): Adds multiple embeddings.addAll(List<String> ids, List<Embedding> embeddings, List<TextSegment> textSegments): Adds multiple embeddings with associated IDs and text segments.removeAll(Collection<String> ids): Delete embeddings by idremoveAll(): Deletes everythingremoveAll(Filter filter): Deletes records using the condition filtersearch(EmbeddingSearchRequest request): Find related embeddingsfindRelevant(Embedding referenceEmbedding, int maxResults, double minScore): Finds relevant embeddings.
- Considerations for Firestore Implementation:
- Data Model: How will you store the embeddings (as float arrays) and associated data (text, metadata)? Firestore uses a NoSQL document model. You’ll likely store each
TextSegmentand itsEmbeddingas a document in a collection. - Metadata: Firestore supports storing metadata as document fields. You’ll need a way to map
TextSegmentmetadata (which is aMap<String, String>) to Firestore document fields. You have a few options here, mirroring what existing modules do:- Individual Columns (Preferred): Each metadata key becomes a separate field in the document. This is efficient for querying but requires knowing the metadata keys in advance. The Mariadb integration uses this approach with
MetadataColumDefinition. - Single JSON Field: Store all metadata as a single JSON string. This is flexible but less efficient for filtering. The Chroma integration uses this.
- Mixed Approach: Common metadata fields (like “source” or “document_id”) could be separate fields, and a catch-all “metadata” field could store the rest as JSON.
- Individual Columns (Preferred): Each metadata key becomes a separate field in the document. This is efficient for querying but requires knowing the metadata keys in advance. The Mariadb integration uses this approach with
- Vector Search: Firestore now has native Vector Search, which is excellent! You’ll use this for the
findRelevantmethod. The key will be understanding how to map LangChain4j’sEmbeddingSearchRequest(which includesmaxResultsandminScore) to the appropriate Firestore vector search query. - Filtering: Implement filtering based on metadata using Firestore’s query capabilities. LangChain4j’s
Filterinterface needs to be translated into a Firestore query. Look at existing implementations likeChromaMetadataFilterMapperfor inspiration, but adapt it to Firestore’s query syntax. - Error Handling: Wrap Firestore exceptions in
RuntimeExceptionor a more specific custom exception. - Configuration: Use a
Builderpattern (likeOpenAiChatModeldoes) to allow users to configure:- Firestore project ID, database, collection name
- Credentials (API key, service account)
- Timeout settings
- Maximum number of results (
maxResults) - Minimum relevance score (
minScore) - Field names for text, embedding, and metadata (if configurable)
- Possibly options for automatically creating the collection/indexes.
- Indexing: You must create the necessary index in Firestore for vector search to work. The documentation you provided explains how to do this with the
gcloudCLI. The code should, ideally, at least check if the index exists. It could even attempt to create it, but this would require more permissions. - Concurrency: if there is any concurrency, the code should be thread-safe.
- Data Model: How will you store the embeddings (as float arrays) and associated data (text, metadata)? Firestore uses a NoSQL document model. You’ll likely store each
- Create
- Implement
GoogleFirestoreEmbeddingModel: You should also implement theEmbeddingModelinterface, by adapting the google API to the langchain4j interface.
Create SPI Builder Factory:
- Create a
GoogleFirestoreEmbeddingStoreBuilderFactoryclass that implementsSupplier<GoogleFirestoreEmbeddingStore.Builder>. - Create a file named
META-INF/services/dev.langchain4j.spi.store.embedding.EmbeddingStoreFactoryinsrc/main/resources. - Add a single line to this file containing the fully qualified name of your factory class (e.g.,
dev.langchain4j.store.embedding.google.firestore.GoogleFirestoreEmbeddingStoreBuilderFactory).
- Create a
Write Integration Tests:
- Create
GoogleFirestoreEmbeddingStoreIT.java(and potentially...WithFilteringIT.java,...WithRemovalIT.java, etc., mirroring the existing modules). - Extend
EmbeddingStoreIT(orEmbeddingStoreWithFilteringIT, etc.) to inherit a basic set of tests. - Implement the abstract methods (like
embeddingStore()) to provide instances of your store and a compatible embedding model. - Add tests specific to Google Cloud Firestore features and limitations.
- Use
@EnabledIfEnvironmentVariableto conditionally run the tests only when the necessary environment variables (credentials) are set. SeeOllamaChatModelITfor an example.
- Create
Add to BOM (Bill of Materials): Add your new module to
langchain4j-bom/pom.xmlto manage its version consistently.Documentation:
- Add the new model in all the
index.mdfiles - Write a guide in
docs/docs/integrations/embedding-stores - Create a README file
- Add the new model in all the
Code Example (Conceptual)
// In your GoogleFirestoreEmbeddingStore.java
package dev.langchain4j.store.embedding.google.firestore;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingMatch;
import dev.langchain4j.store.embedding.EmbeddingStore;
import lombok.Builder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.List;
// ... other imports ...
public class GoogleFirestoreEmbeddingStore implements EmbeddingStore<TextSegment> {
private static final Logger log = LoggerFactory.getLogger(GoogleFirestoreEmbeddingStore.class);
// ... (fields for Firestore client, collection name, etc.) ...
@Builder
public GoogleFirestoreEmbeddingStore(...) {
// ... (initialize Firestore client, etc.) ...
}
@Override
public String add(Embedding embedding) {
// ... implementation ...
}
@Override
public void add(String id, Embedding embedding) {
// ... implementation ...
}
@Override
public String add(Embedding embedding, TextSegment textSegment) {
// ... implementation ...
}
@Override
public List<String> addAll(List<Embedding> embeddings) {
// ... implementation ...
}
@Override
public void addAll(List<String> ids, List<Embedding> embeddings, List<TextSegment> embedded) {
// ... implementation ...
}
@Override
public List<EmbeddingMatch<TextSegment>> findRelevant(Embedding referenceEmbedding, int maxResults, double minScore) {
// ... implementation using Firestore vector search ...
// ... map Firestore results to EmbeddingMatch objects ...
}
// ... other methods ...
}
// In a separate file: GoogleFirestoreEmbeddingStoreBuilderFactory.java
package dev.langchain4j.store.embedding.google.firestore;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.spi.store.embedding.EmbeddingStoreFactory;
public class GoogleFirestoreEmbeddingStoreBuilderFactory implements EmbeddingStoreFactory {
@Override
public GoogleFirestoreEmbeddingStore.Builder get() {
return GoogleFirestoreEmbeddingStore.builder();
}
}
Key Improvements and Considerations from the examples:
- Error Handling: Wrap Firestore API calls in
try-catchblocks and throwRuntimeException(or a more specific custom exception) to handle potential errors. - Logging: Use SLF4J (
log.debug(),log.info(),log.warn(),log.error()) for logging. This is crucial for debugging and monitoring. - Configuration: The
Buildershould allow configuration of all necessary parameters (endpoint, credentials, collection name, timeouts, etc.). UseensureNotNullandensureNotBlankto validate. - Dependency Management: The
pom.xmlshould correctly specify the Google Cloud Firestore client library as a dependency. - Testcontainers: Consider using Testcontainers for integration tests to spin up a Firestore emulator. This will make your tests more reliable and portable. (See examples in the provided code, such as for
CassandraEmbeddingStoreDockerIT). - Metadata: Implement proper handling of metadata, including mapping it to/from Firestore document fields. Decide on your strategy (separate fields vs. JSON).
- Filtering: Implement filtering based on metadata using Firestore’s query capabilities. You will likely need a helper class like
ChromaMetadataFilterMapperto translateFilterobjects into Firestore queries. - Service Provider Interface (SPI): The
spipackage andMETA-INF/servicesfile are critical for LangChain4j to discover your implementation. This is howAiServices(and other parts of the framework) dynamically load components. Without this, your module won’t be usable. - Return type: The
findRelevantmethod should take a {@link dev.langchain4j.store.embedding.EmbeddingSearchRequest} and return a {@link dev.langchain4j.store.embedding.EmbeddingSearchResult}. This would ensure that we have consistency through all embedding stores and allow advanced filtering and reranking features. - Interface segregation: Introduce a
EmbeddingStoreWithFilteringinterface, that extendsEmbeddingStoreand adds aremoveAll(Filter filter)method. - Metadata handling: Implement the
MetadataHandlerinterface, or extend one of its base classes if it’s a good fit. - Support Vector Search API in different database modes: Support vector search in the different modes of Cosmos DB, implementing the search in each of them.
- Implement the
close()method: You should close the connection to Firestore in theclose()method. - Test your embedding store against the
EmbeddingStoreWithFilteringITandEmbeddingStoreWithRemovalIT: The providedlangchain4j-corecontains those abstract test classes that you can use to test your embedding store. - Add documentation: Create Markdown files in the
docs/docs/integrations/embedding-storesdirectory, following the structure of existing integrations. - Add an example: to the examples repository.
By following these steps and adapting the provided example code, you can create a robust and well-integrated LangChain4j module for Google Cloud Firestore.
Second verdict
Again, it’s pretty spot on and acurate! Still a mention to Lombok, or a strange reference to Cosmos DB, but I generally like how it advises me to look at existing modules, telling me that this particular one may be a good inspiration to get my implementation right.
I’ve never implemented an embedding store so far, and I think newer models should implement a search() method instead of findRelevant().
So I asked how to implement this method, using the documentation of the Firestore Java SDK, and a minute later, it suggested a concrete implementation.
I won’t copy the output again, as I don’t want to make this article too long (it already is).
I haven’t tried this implementation, but the code and explanations seemed pretty convincing, so when I get some time, I’ll try to see if it’s correct.
Conclusion
Only Gemini proposes a 2 million token context window. And I’m glad it does, because the LangChain4j projects is close to that limit! With models with smaller windows, I would have had to be way more selective, and send in the prompt just the right types of artifacts (ie. just the LLM modules, or just the embedding store implementations). Thanks to the huge window, I was able to feed the whole repository in its entirety!
Does it mean it’s the end to writing proper tutorials or how-to guides? Certainly not. But I find that very interesting that I’m able to have this kind of highly detailed conversation with the LLM, without having to understand all the tiny little details of the underlying project, as the model is able to grok it for me, and distills just the right level of information for me to do the task I asked about.
What’s very interesting is that I can continue the conversation to go in various directions, or zoom on some specific aspects, which may not necessarily be covered by existing tutorials or guides. It’s as if I was pair programming with the founder of the project.