In-browser semantic search with EmbeddingGemma

A few days ago, Google DeepMind released a new embedding model based on the Gemma open weight model: EmbeddingGemma. With 308 million parameters, such a model is tiny enough to be able to run on edge devices like your phone, tablet, or your computer.
Embedding models are the cornerstone of Retrieval Augmented Generation systems (RAG), and what generally powers semantic search solutions. Being able to run an embedding model locally means you don’t need to rely on a server (no need to send your data over the internet): this is great for privacy. And of course, cost is reduced as well, because you don’t need to pay for a remote / hosted embedding model.
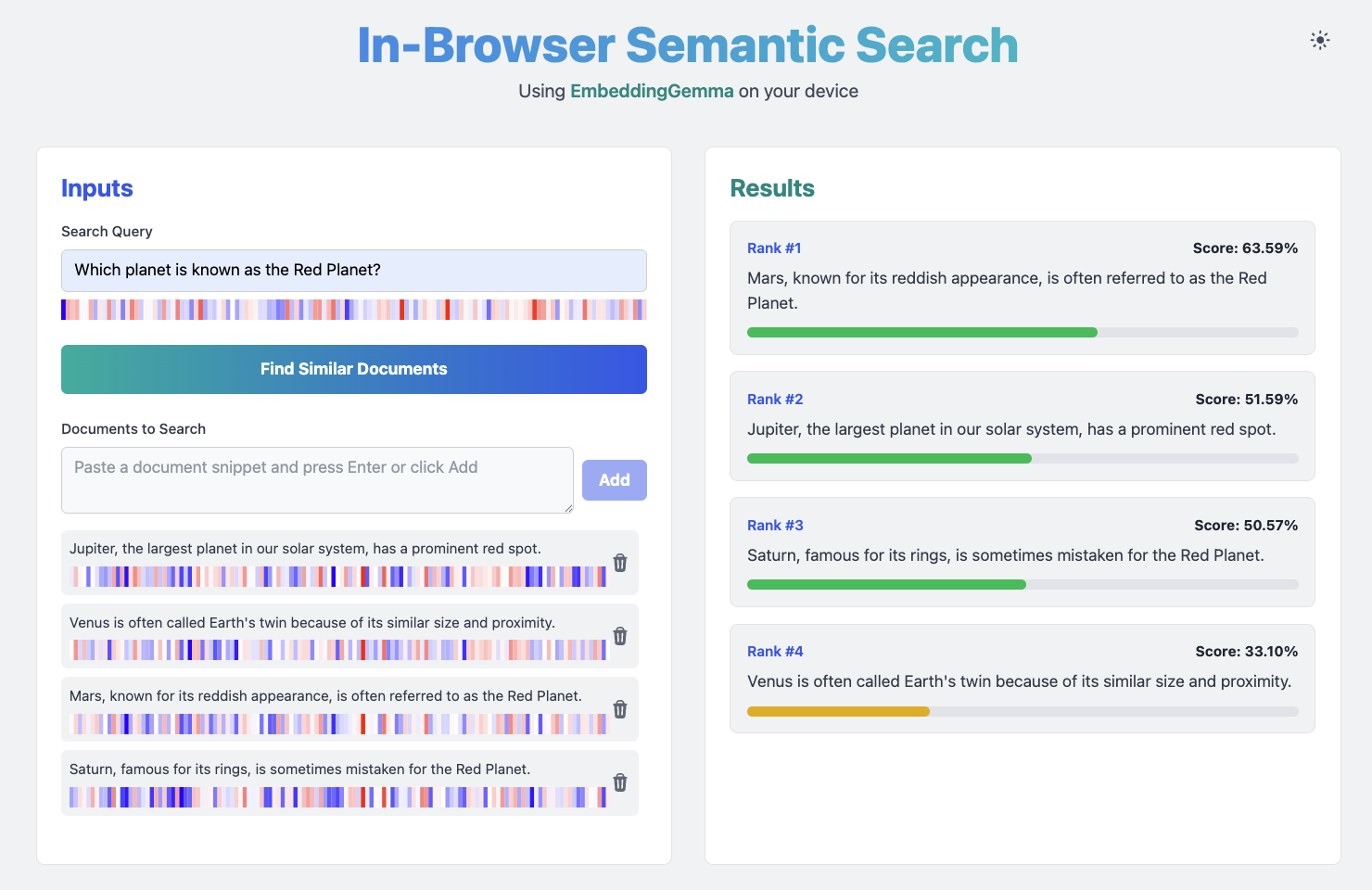
In this article, I’ll walk you through how I built a simple semantic search application. This web app allows users to add a collection of documents, type a query, and instantly get a ranked list of the most relevant documents based on their semantic similarity.
I’ll show you how I brought this to life using the following stack:
- The embedding model: Google’s new, lightweight EmbeddingGemma model.
- The inference engine: 🤗 HuggingFace’s Transformers.js library, which runs the model directly in the browser.
- The UI: A simple and clean interface built with Vite, React, and Tailwind CSS.
- The deployment: A fully automated CI/CD pipeline using GitHub Actions to deploy the static site to 🔥 Firebase Hosting.
Ready to see how it’s done? Let’s dive in.
For those who are in a hurry, feel free to check out the live demo or browse the source code on GitHub:
- Live Demo: https://embedding-gemma.web.app/
- GitHub Repository: https://github.com/glaforge/embedding-gemma-semantic-search
For the demo, 1️⃣ first click to load the weights of the model, 2️⃣ then add a few documents in the database, 3️⃣ finally you can ask a question, 4️⃣ and find the most relevant documents.
Why run AI in the browser?
Running an AI model (here an embedding model) directly on the client-side might seem unconventional considering the best models are usually too big to run on edge devices, but it offers a compelling set of advantages, especially for applications like this one:
- Privacy: Since all the data processing and embedding calculations happen on the user’s device, no sensitive information ever leaves the browser. The documents and queries are never sent over the network, making it a perfect solution for applications that handle personal or confidential text.
- Zero added server costs: The “backend” is the user’s browser. No need for an expensive GPU-powered servers to run the AI model. The application itself is just a set of static files, which can be hosted for free on services like 🔥 Firebase Hosting or GitHub Pages. Of course, the rest of your application may need servers, but at least this part isn’t tied to a server.
- Low latency: With the model running locally, there’s no network round-trip to a server. Once the model weights are loaded in memory, search queries are processed instantly, providing a snappy and responsive user experience. Well, at least as long as you don’t have many millions of documents to search through, as it’ll scale linearly without a proper vector database.
- Offline-first capability: After the initial load, the entire application and the AI model can be cached by the browser (and the data be stored in the browser’s database or local storage), allowing it to function perfectly even without an internet connection.
The core components: a model and a library
At the heart of my application are two key pieces of technology that make in-browser semantic search possible:
The model: EmbeddingGemma
The “brain” of the search is EmbeddingGemma, the new, state-of-the-art (SOTA) text embedding model from Google. Unlike massive language models designed for generating text, embedding models are specialized for a different task: converting a piece of text into a numerical vector (a list of numbers). This vector represents the text’s semantic meaning. The closer two vectors are to each other in mathematical space, the more similar their meanings are.
EmbeddingGemma is the perfect choice for this project for several reasons:
- High performance, small size: It is the highest-performing model of its size (under 500M parameters) on the multilingual Massive Text Embedding Benchmark (MTEB). Built on the Gemma 3 architecture, it’s designed for on-device applications where resources are limited.
- On-device efficiency: With quantization, the model’s memory footprint can be less than 200MB, making it ideal for running in a web browser without overwhelming the user’s device.
- Matryoshka Representation Learning (MRL): While the model produces a high-quality, full-size embedding with 768 dimensions, MRL allows us to truncate that vector to a smaller size (512, 256, or 128 dimensions) with a minimal loss in accuracy. This gives us a good trade-off between performance and computational cost. In my application, I use the first 128 dimensions for the vector visualizations, which is a perfect example of MRL in action.
- Multilingual support: The model was trained on data from over 100 languages. This is quite rare for an embedding model of that size to be good across a wide variety of spoken languages.
The library: Transformers.js
The “engine” that runs the model is Transformers.js from 🤗 HuggingFace. This cool JavaScript library is designed to run a wide variety of popular AI models directly in the browser. It handles all the complex, low-level work of loading the model, managing the cache, and executing the computations efficiently using the browser’s and device’s capabilities.
Transformers.js make it simple to run a model like EmbeddingGemma on the client-side. With it, as shown in 🤗 HuggingFace’s blog post; it only takes a few lines of code to get a model up and running, as we’ll see in the next section.
How the code works
While the UI is a standard React application built with Vite and styled with Tailwind CSS, the most interesting part is the embeddingService.ts file, which acts as a wrapper around the Transformers.js library.
I actually vibe-coded the whole application thanks to Google AI Studio and Gemini CLI. As I’m not an expert in React or TypeScript, that was easier to guide Gemini to make it create the UI I wanted, and I fed Gemini also the code in the 🤗 HuggingFace article to get started with the inference.
Let’s look at a simplified version of the core logic.
Initializing the model
First, I needed to create a singleton instance of the service. This ensures I only ever initialize one copy of the model. The getInstance method handles this, and the init method does the heavy lifting, by calling the AutoTokenizer.from_pretrained() and AutoModel.from_pretrained() method, for loading the text tokenizer and the model respectively.
import { AutoTokenizer, AutoModel } from "@huggingface/transformers";
class EmbeddingService {
private tokenizer: AutoTokenizer | null = null;
private model: AutoModel | null = null;
// ... singleton logic ...
private async init() {
// Load the tokenizer and model from the /model/ directory
this.tokenizer = await AutoTokenizer.from_pretrained("/model/");
this.model = await AutoModel.from_pretrained("/model/", {
dtype: "q4", // Use a quantized version for efficiency
});
}
}
The model can also be loaded from 🤗 HuggingFace’s Hub, but I wanted the model to be local as well, for a faster loading experience and for a full local-first approach.
Generating embeddings and calculating similarity
Once the model is ready, it can be fed the query and documents. The model expects specific prefixes for queries and documents to perform best (task: search result | query: and title: none | text:), so I made sure to add those first.
The core steps are:
- Tokenize: Convert the text (query and documents) into tokens that the model can understand.
- Embed: Pass the tokens to the model to get the sentence embeddings.
- Calculate similarity: Use a matrix multiplication (
matmul) of the embeddings with their transpose to get a similarity score between the query and every document.
// ... inside the EmbeddingService class ...
async embed(query: string, documents: string[]) {
// ...
// Add the required prefixes for the model
const prefixedQuery = "task: search result | query: " + query;
const prefixedDocs = documents.map(doc => "title: none | text: " + doc);
// 1. Tokenize the inputs
const inputs = await this.tokenizer([prefixedQuery, ...prefixedDocs], {
padding: true,
truncation: true,
});
// 2. Get the sentence embeddings
const { sentence_embedding } = await this.model(inputs);
// 3. Calculate the similarity scores
const scores = await matmul(sentence_embedding, sentence_embedding.transpose(1, 0));
// The first row of the scores matrix contains the similarity
// of the query to all other documents.
const similarities = (scores.tolist() as number[][])[0].slice(1);
// ... logic to rank documents based on scores ...
}
And that’s the core of it! With just these two methods (init() and embed()), I had a fully functional semantic search engine running in the browser.
Visualizing the embeddings
To make the concept of semantic similarity more tangible, I added a simple visualization for each document’s embedding vector and the search query. As soon as you type a few characters in the search query input field, or when you add a new document, you’ll see a colored representation of its vector.
Each cell in the visualization represents one of the numbers in the embedding vector, with its color intensity indicating the value. When you compare the visualizations of the query and a relevant document, you can often spot visual similarities in their patterns, offering an intuitive glimpse into how the model “sees” the relationships between texts.
This is where the Matryoshka Representation Learning (MRL) feature of EmbeddingGemma truly shines. The full embedding vector has 768 dimensions, which would be too much to display effectively. Thanks to MRL, I can use just the first 128 dimensions of the vector for this visualization with a minimal loss of semantic information. This provides a compact and meaningful visual fingerprint of the text’s meaning.
The deployment pipeline: CI/CD with a twist
A key challenge with this project was handling the model files.
Although I’m using quantized versions of the weights, they are still quite heavy in megabytes, which is far too large to commit to a Git repository.
However, the application needs these files to be present in the public/model directory to function.
I solved this with a clever CI/CD pipeline using GitHub Actions. Instead of storing the model in my repository, I download it on-the-fly during the deployment process. Since the model files are local, when the application starts, they are faster to load than when loading them from 🤗 HuggingFace’s hub.
Here’s the relevant snippet from my .github/workflows/firebase-hosting-merge.yml file:
jobs:
build_and_deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Download Model
run: |
sudo apt-get install git-lfs
git lfs install
git clone https://huggingface.co/onnx-community/embeddinggemma-300m-ONNX public/model
- run: npm ci && npm run build
- uses: FirebaseExtended/action-hosting-deploy@v0
with:
repoToken: ${{ secrets.GITHUB_TOKEN }}
firebaseServiceAccount: ${{ secrets.FIREBASE_SERVICE_ACCOUNT_EMBEDDING_GEMMA }}
# ... other options
This workflow does the following every time I push to the main branch:
- Checks out my code.
- Downloads the model: It installs
git-lfsand clones the model files directly from the 🤗 HuggingFace Hub into thepublic/modeldirectory. Note that it’s certainly possible to cache the outcome of the model weight checkout though, to make the CI/CD pipeline snappier. - Builds the app: It runs
npm ci && npm run build, which creates the staticdistfolder. Because the model is now in thepublicdirectory, Vite automatically includes it in the build output. - Deploys: It sends the final
distfolder, now containing the model, up to 🔥 Firebase Hosting.
This approach gives me the best of both worlds: a lightweight Git repository and a fully functional, self-contained application deployed to users.
Conclusion
Google AI Studio and the Gemini CLI allowed me to easily build a demonstration app for running EmbeddingGemma on the client-side via Transformers.js.
This application requires no server (apart from the the static assets hosting), is privacy-focused (your data is never sent over the internet), and is cost-effective as its semantic search engine runs entirely in the browser.
I hope this project demonstrates the growing potential of client-side AI and small models (both embedding and language models).
I encourage you to explore the project and see it in action for yourself:
- Live Demo: https://embedding-gemma.web.app/
- Note: The first time you open the application, it will need to load the model files. You’ll see a loading indicator, and once it’s complete, you’ll be able to start searching.
- GitHub Repository: https://github.com/glaforge/embedding-gemma-semantic-search