Advanced RAG — Understanding Reciprocal Rank Fusion in Hybrid Search
Today, let’s come back to one of my favorite generative AI topics: Retrieval Augmented Generation, or RAG for short.
In RAG, the quality of your generation (when an LLM crafts its answer based on search results) is only as good as your retrieval (the actually retrieved search results).
While vector search (semantic) and keyword search (BM25) each have their strengths, combining them often yields the best results. That’s what we often call Hybrid Search: combining two search techniques or the results of different searches with slight variations.
But how do you meaningfully combine a cosine similarity score of 0.85 (from vector search) with a BM25 score of 12.4?
Those values are on two distinct unrelated scales!
Enter Reciprocal Rank Fusion (RRF).
I vibe-coded a little RRF simulator that shows how two lists of documents are ranked into one. For the impatient, feel free to go ahead and play with it, otherwise, you’ll find more information at the bottom of this article on how to use this simulator.

What is RRF?
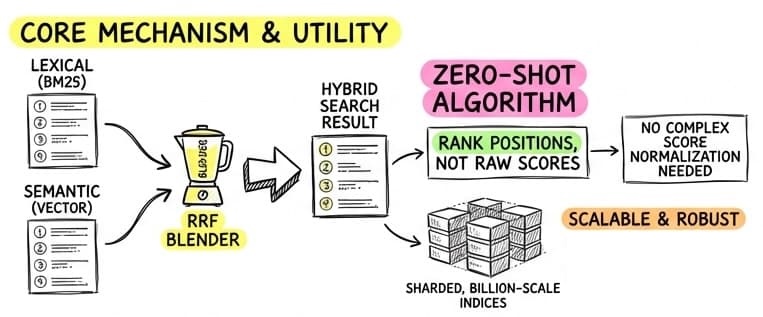
RRF is a robust, “zero-shot” algorithm for merging search results from different retrieval methods. The technique was formally introduced by Gordon V. Cormack and his colleagues in their 2009 SIGIR paper, “Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods”.
Instead of trying to somehow normalize arbitrary scores, RRF ignores the scores entirely and focuses on rank.
It operates on a simple premise: Documents that appear at the top of multiple lists are likely the most relevant. In their research, the authors found that RRF consistently outperformed individual search systems and more complex fusion methods, providing a stable and scalable way to combine diverse ranking signals.
The Formula Simplified
The RRF score for a document is calculated as:
- : The position of the document in a specific search result list (1st, 2nd, etc.).
- : A smoothing constant, typically set to 60.
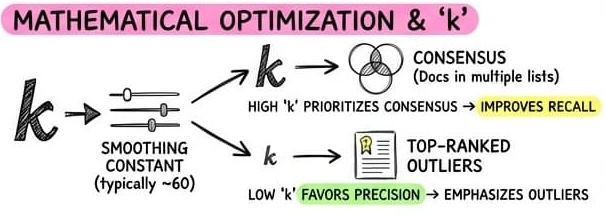
Why is so important?
Think of as a “balance” dial.
- If is low (e.g., 1): The formula gives a massive advantage to the top-ranked items. This configuration favors Precision — trusting that the absolute top results are correct and allowing a single high-performing retriever to dominate.
- If is high (e.g., 60): The advantage of being #1 shrinks. This configuration improves Recall and Consensus. It ensures that even if the “perfect” result is buried at rank #10 across multiple lists, it will still rise to the top.
Why use 60? By setting (the industry standard), RRF prioritizes consensus over individual outliers. It ensures that a document appearing consistently (e.g., ranked #10 in both keyword and vector search) will score higher than a document that is #1 in only one list but completely missing from the others.
It rewards documents that multiple algorithms agree on, rather than letting a single outlier dominate the results.
RRF is fundamentally designed to find consensus. This means it works best when your different retrieval methods are looking at the same overall set of documents and return some overlaps.
If your search results are totally disjoint (meaning no document appears in more than one list), RRF will simply interleave the results: you’ll get the #1 from list A, then #1 from list B, followed by the #2 from list A, and so on. The algorithm only truly begins to “fuse” and re-sort the results when documents start appearing in multiple lists.
Why Use RRF in RAG?
- Normalization Free: You don’t need to know the distribution of your vector or BM25 scores. RRF works purely on position.
- Scalability: It’s extremely efficient for sharded, billion-scale indices where global score normalization is expensive.
- Candidate Selection: RRF is an excellent “first stage” reranker. A common pattern is to retrieve the top 100 documents via RRF, and then use a more expensive (but precise) Cross-Encoder (a reranker model) to rank the top 10 for the LLM context window (see below more for details).
The Two-Stage Architecture: RRF + Cross-Encoder
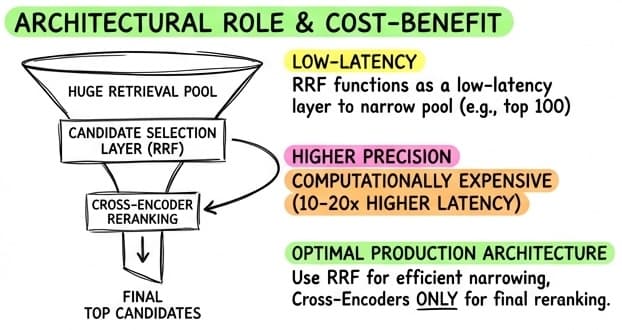
While RRF is excellent at merging lists, it lacks deep semantic understanding of the query-document relationship. This is where Cross-Encoders shine — models like BERT that score the actual interaction between query and text. However, they are computationally expensive and slow.
The industry standard pattern is a “Two-Stage” architecture:
- Stage 1 (Candidate Selection): Use Hybrid Search (Vector + Keyword) fused with RRF to retrieve a broad pool of candidates (e.g., top 100). This ensures high Recall — the right answer is likely somewhere in this list.
- Stage 2 (Precision Reranking): Pass only these top 100 candidates to a Cross-Encoder. The model re-scores them based on deep relevance, picking the absolute best 5-10 chunks for the LLM’s context window.
This pipeline gives you the best of both worlds: the speed and breadth of RRF with the precision of a Cross-Encoder.
Going Further: RAG-Fusion
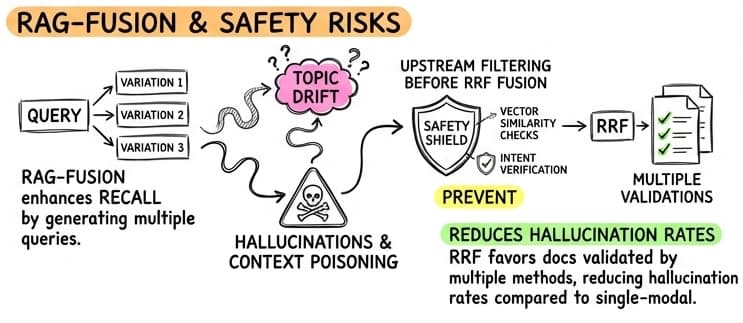
RAG-Fusion takes the hybrid approach a step further. This technique was introduced by Zackary Rackauckas in the 2024 paper, “RAG-Fusion: a New Take on Retrieval-Augmented Generation”. It uses an LLM to generate multiple variations of the user’s original query to “broaden the net” and find relevant context that a single query might miss.
The process follows a clever loop:
- Multi-Query Generation: An LLM generates 3-5 different versions of the user’s query (e.g., synonyms, rephrasings, or breaking down a complex question).
- Parallel Retrieval: Each variation is sent to the search engine (both Vector and Keyword).
- RRF Aggregation: All resulting lists are fused using RRF.
By using RRF to merge results from multiple query variations, the system naturally filters out “topic drift.” Documents that appear consistently across many query variants rise to the top, while noise from a single poor query variation is pushed down. This “consensus” approach significantly reduces hallucination rates by ensuring the LLM is provided with content validated by multiple search angles.
RRF in the Wild: LangChain4j
RRF isn’t just a theoretical concept; it’s a standard component in modern AI stacks. LangChain4j, the popular Java library for building LLM-powered applications, uses RRF as its default mechanism for aggregating results from multiple sources.
The DefaultContentAggregator class in LangChain4j employs a ReciprocalRankFuser to merge ranked lists of content.
This means if you configure a RAG pipeline with multiple retrievers (e.g., one for recent web data and one for internal documents),
LangChain4j automatically applies RRF to give you the best of both worlds without any manual tuning.
Here is how you can set up a hybrid retrieval system in LangChain4j that implicitly uses RRF:
// 1. Define your retrievers
ContentRetriever bm25Retriever = ...;
ContentRetriever vectorSearchRetriever =
EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(10)
.build();
// 2. Combine them in the RetrievalAugmentor
// DefaultRetrievalAugmentor uses
// DefaultContentAggregator which uses RRF
RetrievalAugmentor retrievalAugmentor =
DefaultRetrievalAugmentor.builder()
.contentRetriever(bm25Retriever)
.contentRetriever(vectorSearchRetriever)
.build();
// 3. Configure the augmentor on the AI service
Assistant assistant = AiServices.builder(Assistant.class)
...
.retrievalAugmentor(retrievalAugmentor)
.build();
By simply adding multiple retrievers, the DefaultContentAggregator kicks in, calculating the
score for every item found by either retriever and re-sorting them into a single, high-quality context for your LLM.
Try the Simulator
To truly understand how the smoothing constant impacts rankings and how different lists merge, I’ve built a Reciprocal Rank Fusion Simulator.
You can experiment with different document rankings and see the fusion math in real-time here: 👉 Launch RRF Simulator
Use this tool to visualize how RRF balances precision (favoring top ranks) vs. consensus (favoring agreement across lists) and tune your intuition for hybrid search architectures.
- Interactive Rank Experimentation: Create new lists, add/remove documents, shuffle the lists, etc. Use drag-and-drop to reorder results in two independent search engines. Since RRF ignores raw scores and focuses only on position, you can see exactly how moving a document up or down one list impacts its final “fused” standing.
- Visualizing Consensus: The simulation demonstrates RRF’s “consensus” logic, indeed documents that appear in both lists (even at mediocre ranks) often outperform documents that rank #1 in only one list. This highlights why hybrid search is so effective.
- Real-Time Parameter Tuning: By adjusting the constant, you can see how the algorithm’s sensitivity changes. You’ll observe how a lower prioritizes “top-heavy” results, while a higher gives more weight to documents found deeper in the search results.
Summary
I hope this article helped you get a better intuition of Reciprocal Rank Fusion, why it’s so useful, and how it works! By focusing on rank rather than arbitrary scores, RRF provides a robust and scalable way to merge diverse search results, making it a cornerstone of modern hybrid search and advanced RAG architectures.