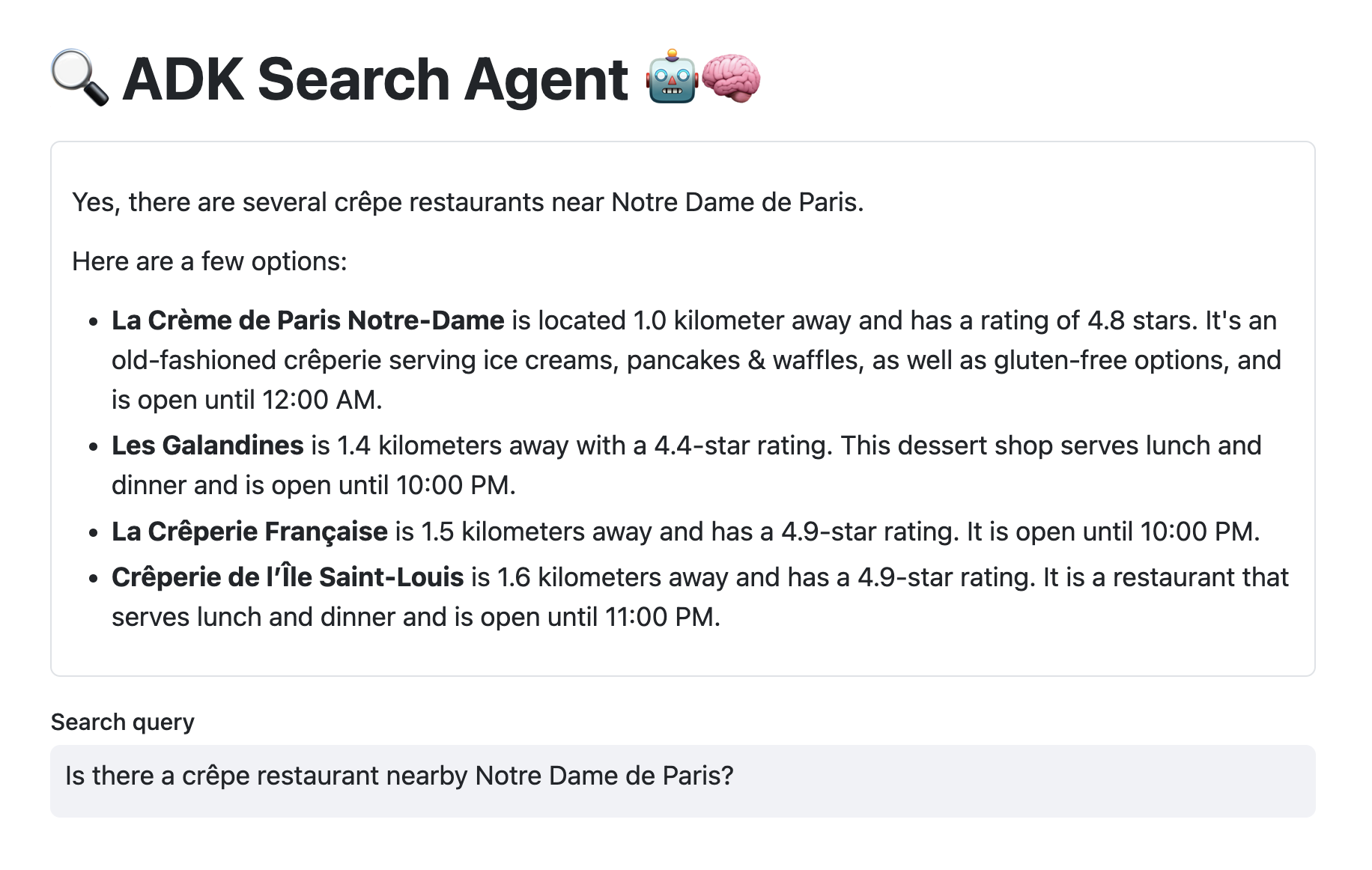
Implementing the Interactions API with Antigravity
Google and DeepMind have announced the Interactions API, a new way to interact with Gemini models and agents.
Here are some useful links to learn more about this new API:
- An announcement is available on Google’s Keywords blog:
Interactions API: A unified foundation for models and agents - A more detailed article is available on Google’s developers blog:
Building agents with the ADK and the new Interactions API - The newly released Gemini Deep Research agent is now available via the Interactions API as well:
Build with Gemini Deep Research - The official documentation of the Interactions API.
About the Interactions API
The Rationale and Motivation
The Interactions API was introduced to address a shift in AI development, moving from simple, stateless text generation to more complex, multi-turn agentic workflows. It serves as a dedicated interface for systems that require memory, reasoning, and tool use. It provides a unified interface for both simple LLM calls and more complex agent calls.
Read more...