Binge streaming web APIs with Ratpack, Cloud Ednpoints, App Engine Flex and Streamdata.io
At Devoxx last week, I had the chance to do a joint tools-in-action with my talented friend Audrey Neveu, titled Binge streaming you Web API:
In a fast-paced fashion, to keep you awake after long University sessions, Audrey and Guillaume will set you up to create a Web API using Google Cloud Endpoints, and stream the content of the API in real-time with Streamdata.io. After a quick introduction to both technologies, they’ll build together both the backend and the front-end to interact live with the audience, through the Web or via a mobile app.
For the impatient, scroll down to the end of the article to access the slides presented, and view a recording of the video!
We split the presentation in two sections: 1) first of all, we obviously need to create and deploy a Web API, and then 2) to configure and use Streamdata.io to stream the updates live, rather than poll the API endlessly.
For the purpose of our demo, Audrey and myself decided to surf on the theme of the conference, by publishing ourselves an API of the conference content, listing all the talks and speakers available.
As the content is pretty much static, we needed some data that would evolve in real-time as well. We added a voting capability, so that users could click on a little smiley to say if they’re enjoying the talk or not. With the streaming capability, as soon as votes are taking place, we update the UI with the new vote results.
Implementing my API with Ratpack
To build the API, I decided to go with the Ratpack framework. As the Ratpack website states:
Ratpack is a set of Java libraries for building modern HTTP applications.
It provides just enough for writing practical, high performance, apps.
It is built on Java 8, Netty and reactive principles.
You can use Ratpack with Java 8, but there’s also a nice Groovy wrapper. So with my Apache Groovy hat on, I naturally chose to go with Groovy!
In the Groovy community, there’s a tool called Lazybones which allows you to create template projects easily. And we’re also using SDKman for installing various SDKs, including SDKman.
If you don’t have lazybones installed (but have SDKman), it’s fairly easy to install:
sdk install lazybones
With both installed already on my machine, I just needed to create a new project with the Ratpack template:
lazybones create ratpack
And I had my template project ready!
Gradle to the rescue to build the app
My Gradle script is pretty straightforward, using the Ratpack Groovy plugin, the Shadow plugin, etc. Nothing really fancy:
buildscript {
repositories {
jcenter()
}
dependencies {
classpath "io.ratpack:ratpack-gradle:1.4.4"
classpath "com.github.jengelman.gradle.plugins:shadow:1.2.3"
}
}
apply plugin: "io.ratpack.ratpack-groovy"
apply plugin: "com.github.johnrengelman.shadow"
apply plugin: "idea"
apply plugin: "eclipse"
repositories {
jcenter()
}
dependencies {
runtime 'org.slf4j:slf4j-simple:1.7.21'
testCompile "org.spockframework:spock-core:1.0-groovy-2.4"
}
To build this app, I’ll use the tar distribution target, which generates startup scripts to be launched from the command-line:
./gradlew distTar
To run the app locally, you can use:
./gradlew run
By default, it runs on port 5050.
The URL paths and methods
For developing my API, I created the following paths and methods:
- GET /api : to list all the talks available
- GET /api/{day} : to restrict the list of talks to just one particular day
- GET /api/talk/{id} : to view the details of a particular talk
- POST /api/talk/{id}/vote/{vote} : to vote on a particular talk (negative, neutral, positive)
- POST /import : to import a JSON dump of all the talks, but it’s just used by me for uploading the initial content, so it’s not really part of my API.
Implementing the API
My Ratpack app implementing this API (plus a few other URLs) spans a hundred lines of Groovy code or so (including blank lines, imports, and curly braces). The implementation is a bit naive as I’m storing the talks / speakers data in memory, but I should have used a backend storage like Cloud Datastore or Cloud SQL, potentially with Memcache in front. So the app won’t scale well and data will not be synchronized across multiple instances running in parallel. For the sake of my demo though, that was sufficient!
import ratpack.handling.RequestLogger
import org.slf4j.LoggerFactory
import static ratpack.groovy.Groovy.ratpack
import static ratpack.jackson.Jackson.json as toJson
import static ratpack.jackson.Jackson.fromJson
def log = LoggerFactory.getLogger('Devoxx')
def allTalks = []
ratpack {
handlers {
all(RequestLogger.ncsa())
post('import') {
log.info "Importing talks dump"
byContent {
json {
parse(fromJson(List)).onError { e ->
String msg = "Import failed: $e"
log.error msg
response.status(400)
render toJson([status: "Import failed: $e"])
}.then { talks ->
allTalks = talks
log.info "Loaded ${allTalks.size()} talks"
render toJson([status: 'Import successful'])
}
}
}
}
prefix('api') {
prefix('talk') {
post(':id/vote/:vote') {
def aTalk = allTalks.find { it.id == pathTokens.id }
if (aTalk) {
def msg = "Voted $pathTokens.vote on talk $pathTokens.id".toString()
switch (pathTokens.vote) {
case "negative":
aTalk.reactions.negative += 1
log.info msg
render toJson([status: msg])
break
case "neutral":
aTalk.reactions.neutral += 1
log.info msg
render toJson([status: msg])
break
case "positive":
aTalk.reactions.positive += 1
log.info msg
render toJson([status: msg])
break
default:
response.status(400)
msg = "'${pathTokens.vote}' is not a valid vote".toString()
log.info msg
render toJson([status: msg])
}
} else {
response.status(404)
render toJson([status: "Talk $pathTokens.id not found".toString()])
}
}
get(':id') {
def aTalk = allTalks.find { it.id == pathTokens.id }
if (aTalk) {
log.info "Found talk: $pathTokens.id"
render toJson(aTalk)
} else {
String msg = "Talk $pathTokens.id not found"
log.info msg
response.status(404)
render toJson([status: msg])
}
}
}
get(':day') {
def talksPerDay = allTalks.findAll { it.day == pathTokens.day }.collect {
it.subMap(it.keySet() - 'summary')
}
if (talksPerDay) {
render toJson(talksPerDay)
} else {
response.status(404)
render toJson([status: "Invalid day, or no talks found for: $pathTokens.day".toString()])
}
}
get {
render toJson(request.queryParams.full ? allTalks : allTalks.collect {
it.subMap(it.keySet() - 'summary')
})
}
}
}
}
Some interesting points about this code:
- use of an NCSA-compliant request logger to log all API calls (following the NCSA usual output pattern) and a dedicated logger for important events, and you’re able to watch both those kind of logs in the Stackdriver logging in the cloud console
- the use of prefix(’…’) to factor common path parts
- Jackson is being used both for parsing (the input file containing the initial list of talks) as well as for output for rendering the JSON payloads
- see how we use byContent / json to handle the requests coming up with content-type of application/json
- the rest is essentially error handling, collection filtering, etc.
Containerizing the app
Ratpack requires JDK 8 to run, and it’s not based on servlets, I went with Google App Engine Flex, which allows me to run JDK 8 / Java 8 apps which can be based on networking toolkits like Netty.
I mentioned we’re using the distTar target to build a distribution of the application, and that’s what we’ll point our Dockerfile at, as App Engine Flex allows you to customize Docker images for bundling and running your app:
FROM gcr.io/google_appengine/openjdk8
VOLUME /tmp
RUN mkdir -p /app/endpoints
ADD service.json /app/endpoints
ADD build/distributions/devoxx-reactions.tar /
ENV JAVA_OPTS='-Dratpack.port=8080 -Djava.security.egd=file:/dev/./urandom'
ENTRYPOINT ["/devoxx-reactions/bin/devoxx-reactions"]
I’m using the dedicated Open JDK 8 image for App Engine, from the Google Container Registry. I’m specifying the port for my app, the entry point to the startup scripts. You’ll notice the lines about “endpoints” and “service.json”, and I’ll come to it in a minute: it’s because I’m using Google Cloud Endpoints to expose and manage my API!
At this point, to feel safer, you can double check that your app is running under docker with something like:
./gradlew distTar
docker build -t devoxx-reactions-image .
docker run -p 127.0.0.1:8080:8080 -it devoxx-reactions-image
The app is running on port 8080 of your localhost. We’ll see later on how to test it with curl, and how to load the sample data that we’ve prepared in public/data/talks.json.
GCloud, to set up our projects
As we’re going to use Cloud Endpoints on App Engine Flex, it’s time that I start setting things up with the gcloud SDK:
gcloud init
gcloud components update
gcloud components install beta
gcloud config set project [YOUR_PROJECT_ID]
About Google Cloud Endpoints
Google Cloud Platform offers a particular service for managing Web APIs called Endpoints. With Endpoints, you’re able to monitor your API (see what endpoints, methods, are called, with some nice graphs and stats), to secure your API (with different kind of authentication like Firebase authentication, JSON Web Tokens, API keys, etc.), to scale it.
Speaking of scaling, I’m using App Engine Flex here as my deployment target, but it’s possible to use Compute Engine or Container Engine as well. Interestingly, you can use Endpoints API management with an API hosted in a third-party cloud, as well as on premises too!
The management aspect of the API is done thanks to a proxy, called the Endpoints Service Proxy, which is implemented on top of NGINX (and which will be open sourced). And to continue on scaling aspect of the story, it’s interesting to note that this proxy is living along your app (in its own container). If your API needs to scale across several machines, instead of one giant middle proxy somewhere, your ESP will be duplicated the same way. So there’s no single point of failure with a gigantic proxy, but it also means that the latency is super low (below 1 ms usually), because the proxy is as close as possible to your API, without needing any additional costly network hop.
The last interesting aspect about Cloud Endpoints that I’d like to mention is that your API contract is defined using OpenAPI Specs (formerly known as Swagger). So it doesn’t matter which language, framework, tech stack you’re using to implement your API: as long as you’re able to describe your API with an OpenAPI Specification, you’re good to go!
Specifying the contract of our API with OpenAPI Spec
I mentioned before the various resources and methods we’re using for our API, and we’ll encode these in the form of a contract, using the OpenAPI Spec definition format. In addition to the various resources and methods, we should also define the payloads that will be exchanged: basically, a Talk, a Result, a list of talks. We must define the different status codes for each kind of response. Here’s what my specification looks like:
---
swagger: "2.0"
info:
description: "Consult the Devoxx schedule and vote on your favorite talks."
version: "1.0.0"
title: "Devoxx Reactions"
contact: {}
host: "devoxx-reactions.appspot.com"
schemes:
- "http"
paths:
/import:
post:
summary: "Import a dump of the lists of talks"
operationId: "ImportTalks"
consumes:
- "application/json"
produces:
- "application/json"
parameters:
- name: "talkList"
in: "body"
required: true
schema:
$ref: "#/definitions/TalkList"
responses:
200:
description: "Status 200"
schema:
$ref: "#/definitions/Result"
400:
description: "Status 400"
schema:
$ref: "#/definitions/Result"
/api:
get:
summary: "Get the list of talks"
operationId: "GetAllTalks"
produces:
- "application/json"
parameters: []
responses:
200:
description: "Status 200"
schema:
type: "array"
items:
$ref: "#/definitions/Talk"
/api/talk/{talk}:
get:
summary: "Get a particular talk"
operationId: "GetOneTalk"
produces:
- "application/json"
parameters:
- name: "talk"
in: "path"
required: true
type: "string"
responses:
200:
description: "Status 200"
schema:
$ref: "#/definitions/Talk"
404:
description: "Status 404"
schema:
$ref: "#/definitions/Result"
/api/talk/{talk}/vote/{vote}:
post:
summary: "Vote for a talk"
operationId: "VoteOnTalk"
produces:
- "application/json"
parameters:
- name: "talk"
in: "path"
required: true
type: "string"
- name: "vote"
in: "path"
description: "The vote can be \"negative\", \"neutral\" or \"positive\""
required: true
type: "string"
responses:
200:
description: "Status 200"
schema:
$ref: "#/definitions/Result"
400:
description: "Status 400"
schema:
$ref: "#/definitions/Result"
404:
description: "Status 404"
schema:
$ref: "#/definitions/Result"
/api/{day}:
get:
summary: "Get the talks for a particular day"
operationId: "GetTalksPerDay"
produces:
- "application/json"
parameters:
- name: "day"
in: "path"
required: true
type: "string"
responses:
200:
description: "Status 200"
schema:
type: "array"
items:
$ref: "#/definitions/Talk"
404:
description: "Status 404"
schema:
$ref: "#/definitions/Result"
definitions:
Result:
type: "object"
required:
- "status"
properties:
status:
type: "string"
description: "Voting results"
Talk:
type: "object"
required:
- "day"
- "fromTime"
- "fromTimeMillis"
- "id"
- "reactions"
- "speakers"
- "talkType"
- "title"
- "toTime"
- "toTimeMillis"
- "track"
properties:
day:
type: "string"
fromTime:
type: "string"
fromTimeMillis:
type: "integer"
format: "int64"
id:
type: "string"
description: ""
reactions:
type: "object"
properties:
negative:
type: "integer"
format: "int32"
neutral:
type: "integer"
format: "int32"
positive:
type: "integer"
format: "int32"
required:
- "negative"
- "neutral"
- "positive"
room:
type: "string"
speakers:
type: "array"
items:
type: "string"
summary:
type: "string"
talkType:
type: "string"
title:
type: "string"
toTime:
type: "string"
toTimeMillis:
type: "integer"
format: "int64"
track:
type: "object"
properties:
title:
type: "string"
trackId:
type: "string"
required:
- "title"
- "trackId"
description: "A talk representation"
TalkList:
type: "array"
items:
$ref: "#/definitions/Talk"
description: "A list of talks"
You can write your API specifications using either JSON or YAML. I chose YAML because it’s a bit easier to read, for the human eye, and still as much readable for the computer as well.
There’s one extra step for instructing Cloud Endpoints about our API definition: I needed to convert my OpenAPI Spec into the service definition format used internally by Cloud Endpoints, thanks to the following command:
gcloud beta service-management convert-config swagger20.yaml service.json
Deploying on App Engine Flex
To deploy on App Engine and use Cloud Endpoints, we’re going to use the gcloud command-line tool again:
gcloud beta app deploy
After a few minutes, your app / API should be available and be ready for serving.
Testing our API
I have a JSON file with the bulk of the talks and their details, so I uploaded it with:
curl -d @src/ratpack/public/data/talks.json -H 'Content-Type: application/json' http://devoxx-reactions.appspot.com/import
And then I was able to call my API with:
curl https://devoxx-reactions.appspot.com/api
curl https://devoxx-reactions.appspot.com/api/monday
curl https://devoxx-reactions.appspot.com/api/talk/HFW-0944
And to vote for a given talk with:
curl -X POST https://devoxx-reactions.appspot.com/api/talk/XMX-6190/vote/positive
Managing your API
When you’re visiting your cloud console, you’ll be able to see interesting statistics and graphs, about the usage of your API:
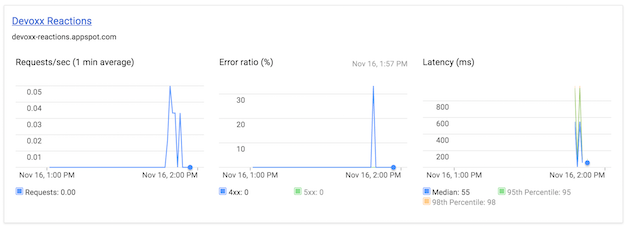
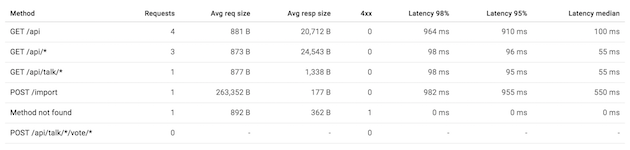
Streaming the API
For the streaming part of the story, I’ll let Audrey cover it! I focused on the backend, how she focused on the Polymer frontend, with a custom Streamdata component, that used the Streamdata proxy to get the patches representing the difference between consecutive calls to the backend. So when the votes were changing (but the rest of the talk details were left unchanged), Streamdata would send back to the front only the diff. In addition to keeping ongoing data exchanges low (in terms of size), the proxy is also able to take care of caching, so it also helps avoiding hitting the backend too often, potentially helping with scalability of the backend, by keeping the cache at the proxy level.
Slides and video available!
You can watch the video online on Devoxx’ YouTube channel:
And you can also have a closer look at the slides as well: